K8s Extensions Server Controller#
在介绍扩展 Server 的控制器之前,我们需要了解一下声明式 API 及其控制器模式。
声明式 API#
本节从一个例子来认识声明式 API。
假设用户在购物网站上购买了一本书,但第二天反悔了,希望取消订单并退款,这时应该如何操作呢?首先用户需要到购物网站打开该订单查看其状态,如果是已经发货甚至已经到货了,则需要点击“售后服务”,联系客服安排退货退款;如果卖家还没有发货,则可以直接点击退款,等待一段时间后退款过程就可以完成。用伪代码来描述这一过程,伪代码如下:
…
if (订单状态为已发货或其后续状态) {
联系客服;
如已收件,联系快递上门取件;
…
}else{
点击退款;
确认退款完成;
}
…以上这个过程代表了当今程序处理的典型过程,用户作为购物网站的使用者需要根据订单状态作出判断,采取正确的操作进行退款。为了正常拿到退款,用户需要具有工作流程的 知识,这是一种负担。这个购物网站的设计不是一种声明式的设计。
作为购物者,对购物网站制定的退款操作规则不感兴趣,想做的只是把订单改为申请退款的状态,希望能购物网站能根据订单当前状态来自我调整,尽一切可能来满足用户要求。也就是说,理想的过程如下:
…
更改订单状态为“申请退款”;
离开网站;
…
接收到系统操作结果的通知;
…能够实现以上过程的设计就是一种声明式的设计。声明式设计产生一种对使用者极为友善的系统,使得使用者摆脱了根据系统现状和流程设计采取不同操作的要求,只需申明希望系统达到的最终状态即可。
与非声明式设计相比,声明式设计在减轻使用者脑力负担的同时,也有其自身的弊端:在复杂系统中一般不会保证使用者即刻获得反馈,其所期望达到的状态也不是当时就可以达到,何时能到完全依赖系统,也就是说使用者已经不能完全控制后续的执行了。
所以说采用声明式设计是 Kubernetes 最大胆的决定。商用系统对于错误和延迟的容忍度一般较低,错误往往意味着损失,延迟代表着低效,都是非常负面的事情。商业软件对于精确和高效十分在意,针对用户的一个操作,系统最好马上给出明确的反馈。
精确高效、使用者低负担和复杂的系统状态转换三者间存在潜在的冲突,可同时取其二但很难三者皆得,如下图所示。例如,我门可以选择精确高效+复杂的系统状态转换,牺牲掉使用者低负担,也就是说通过让使用者明确指出执行过程来克服复杂性带来的处理延迟;也可以选择精确高效+使用者低负担,这时就要把你的系统状态转换设计得简单明了一些,从而减少系统在转换状态时的巨大开销。声明式设计选择了使用者低负担+复杂的系统状态转换,而牺牲掉精确高效。
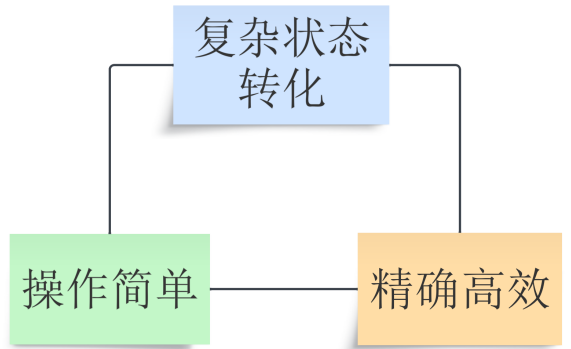
Kubernetes 用户使用系统的主要媒介是 API 资源实例,系统用户通过创建、调整 API 实例来提出自身需求,Kubernetes 系统以异步方式,按照既定逻辑,逐一响应这些需求,过程中无需用户参与。这种请求与响应的模式符合声明式设计,称为声明式 API。下面通过 Kubernetes 滚动更新机制来体验声明式 API 带给使用者的优秀体验。
滚动更新#
应用程序提供者希望部署在 Kubernetes 集群中的应用 7*24h 可用,这样业务就可以不间断从而避免任何损失。但程序可能由于各种客观原因停机,典型的是升级,新版年本替换老版本。在 Kubernetes 出现前,这是一个老大难问题,需要操作人员大量的精心准备。以容器为基础的云原生架构从容地解决了这个问题,因为云原生应用支持多实例并不是什么难事,底层平台可以通过逐步替换实例到新版本的方式,在不停止服务的前提下完成升级。 Kubernetes 平台上这种机制是滚动更新。
设想有如下微服务,其核心业务代码放在镜像 M 中,Pod A、B、C 运行该镜像来输出服务,由于所运行镜像一致,ABC 三者服务也完全一致,互相可替代,它们都由一个 Deployment 资源实例来管理,而 Deployment 又是通过一个 ReplicaSet 实际管理 Pod 的;系统通过 Service S 把这个微服务在集群内暴露,供其它服务调用。各元素相互关系如图:
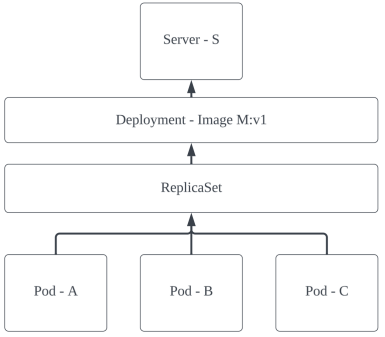
初始时镜像 M 的版本是 v1, 管理容器 A,B,C 的 Deployment 资源定义文件如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
labels:
app: my-service
spec:
replicas: 3
selector:
matchLabels:
app: my-service
template:
metadata:
labels:
app: my-service
spec:
containers:
- name: service-s
image: M:v1
ports:
- containerPort: 80现在把镜像 M 的版本升级到 v2, 管理员将 Deployment 的资源定义文件做如下修改,提交给 API Server 即可:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
labels:
app: my-service
spec:
replicas: 3
selector:
matchLabels:
app: my-service
template:
metadata:
labels:
app: my-service
spec:
containers:
- name: service-s
image: M:v2
ports:
- containerPort: 80正常情况下,这是管理员所有需要做的操作!只需指出新版本镜像,不必描述新老版本的替换步骤,该过程完全由系统自主决定。以上修改触发了 Kubernetes 滚动更新机制,该 机制分多次关停现有 Pod A,B,C,保证时刻有容器对外提供服务,再启动相同数量的运行 M:v2 镜像的容器,并划归原 Deployment 管理,直到全部 Pod 被更新至 v2。
NOTE:
这里略去了滚动更新的配置和执行细节,每次最多停掉多少 Pod、最少保证有多少 Pod 存在等,都可以通过配置指定。
在以上例子中,Kubernetes 不要求用户手动关停 Deployment 中各个 Pod,然后启动新 Pod 去更新,也不要求用户指定是先关后启还是反之,诸如此类细节都交给系统处理了,使用者只需通过变更 API 实例 (Deployment) 的定义文件阐明期望的状态。这充分体现了声明式设计带来的卓越用户体验。
控制器模式#
声明式 API 非常酷,但实现它却需要一番考量。Kubernetes 设计出控制器模式来实现它,该模式执行过程如下图所示。
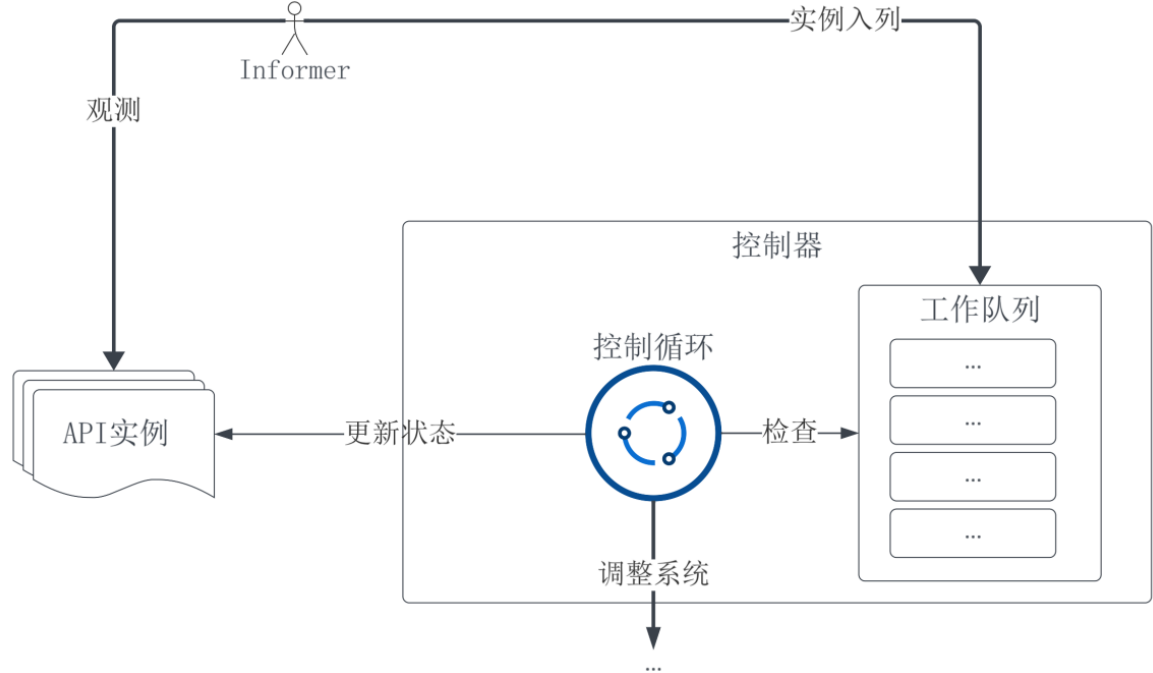
一个 API 背后有一个叫做控制器(Controller)的对象,控制器可以被理解为一段无限循环程序,除非被人为终止它会一直运行。这个永不停止的循环被称为控制循环。控制循环的第一项工作是查看自上次循环运行完毕后,有哪些该种类 API 实例被创建、修改或删除, 这是借助一个工作队列来完成的:工作队列会记录这些定义发生变动的实例,为控制循环提供工作目标。
控制循环从队列中取出待处理 API 实例,读出该 API 实例的期望状态和当前实际状态,它们分别记录在资源描述的 spec 和 status 部分,根据二者的差异得出需要的操作并执行。如果成功变更到目标状态,控制循环会更新实例的状态描述,并从工作队列中移除这个该实例;相反如果操作无法完成,则控制器会保留资源实例在工作队列中,以待下次循环再次尝试处理。
上述描述的整个过程被称为控制器模式。为了更深入理解控制器和控制器模式,下面小节来解析 Kubernetes 的 Job 控制器源码。
Job 控制器#
Job 代表可由系统在无人值守的情况下自主一次性完成的工作,具体的工作事项可以由一个或多个 Pod 去执行。Job 控制器的主要工作内容:
- 为新 Job 创建 Pod。
- 跟踪 Pod 的状态,对成功和失败进行计数,并据此更新 Job 的状态。
这里忽略了控制器中非核心的工作,只关注重点。下面到 Job 控制器源码文件看一下控制器基座结构体,代码如下所示:
// 代码: pkg\controller\job\job_controller.go#L84-L133
// Controller ensures that all Job objects have corresponding pods to
// run their configured workload.
type Controller struct {
kubeClient clientset.Interface
podControl controller.PodControlInterface
// To allow injection of the following for testing.
updateStatusHandler func(ctx context.Context, job *batch.Job) (*batch.Job, error)
patchJobHandler func(ctx context.Context, job *batch.Job, patch []byte) error
//要点①
syncHandler func(ctx context.Context, jobKey string) error
// podStoreSynced returns true if the pod store has been synced at least once.
// Added as a member to the struct to allow injection for testing.
podStoreSynced cache.InformerSynced
// jobStoreSynced returns true if the job store has been synced at least once.
// Added as a member to the struct to allow injection for testing.
jobStoreSynced cache.InformerSynced
// A TTLCache of pod creates/deletes each rc expects to see
expectations controller.ControllerExpectationsInterface
// finalizerExpectations tracks the Pod UIDs for which the controller
// expects to observe the tracking finalizer removed.
finalizerExpectations *uidTrackingExpectations
// A store of jobs
jobLister batchv1listers.JobLister
// A store of pods, populated by the podController
podStore corelisters.PodLister
// podIndexer allows looking up pods by ControllerRef UID
podIndexer cache.Indexer
// Jobs that need to be updated
//要点②
queue workqueue.TypedRateLimitingInterface[string]
// Orphan deleted pods that still have a Job tracking finalizer to be removed
orphanQueue workqueue.TypedRateLimitingInterface[orphanPodKey]
broadcaster record.EventBroadcaster
recorder record.EventRecorder
clock clock.WithTicker
// Store with information to compute the expotential backoff delay for pod
// recreation in case of pod failures.
podBackoffStore *backoffStore
// finishedJobExpectations contains the job ids for which the job status is finished
// but the corresponding event is not yet received.
finishedJobExpectations sync.Map
}要点①和②处定义了两个重要结构体字段:syncHandler 和 queue,它们在控制循环中起到如下作用:
queue:这是控制循环的工作队列,内含待处理的 Job 资源实例的 ID,包括待创建、已修改和未完成的 Job,一次循环的启动是从检测队列内容开始的。syncHandler:一个方法,控制循环的核心业务逻辑,每次运行最终会跑这个方法。
虽然 Kubernetes 的控制器多种多样,但它们的实现思路极为类似,以上两个属性几乎在任何控制器内都可以找到,这样的设计安排使得代码更易阅读。除了字段,基座结构体还具有诸多方法,其中 Run(),processNextWorkItem(),syncJob(),worker(),manageJob() 和 trackJobStatusAndRemoveFinalizers() 方法对理解 Job 控制器及其工作机制至关重要,它们之间的调用关系如图所示;
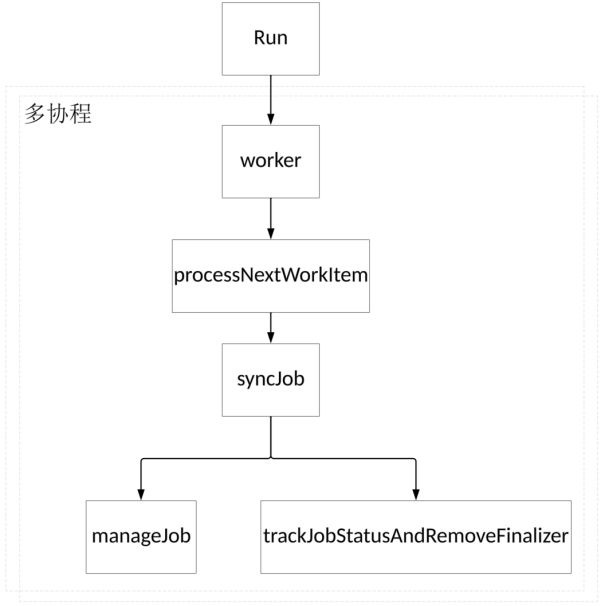
1. Run() 方法#
Run() 方法是控制器的启动方法。它首先启动工作队列,然后启动指定数量的协程,如有协程中途退出,1 秒后再次启动之;每个协程不断运行 worker 方法去处理 queue 中的 Job 资源,体现在以下代码的要点①处。当控制器停止运行时会做一些错误处理和清理工作,由 defer 关键字修饰的语句完成。
// Run the main goroutine responsible for watching and syncing jobs.
func (jm *Controller) Run(ctx context.Context, workers int) {
defer utilruntime.HandleCrash()
logger := klog.FromContext(ctx)
// Start events processing pipeline.
jm.broadcaster.StartStructuredLogging(3)
jm.broadcaster.StartRecordingToSink(&v1core.EventSinkImpl{Interface: jm.kubeClient.CoreV1().Events("")})
defer jm.broadcaster.Shutdown()
defer jm.queue.ShutDown()
defer jm.orphanQueue.ShutDown()
logger.Info("Starting job controller")
defer logger.Info("Shutting down job controller")
if !cache.WaitForNamedCacheSync("job", ctx.Done(), jm.podStoreSynced, jm.jobStoreSynced) {
return
}
// 要点①
for i := 0; i < workers; i++ {
go wait.UntilWithContext(ctx, jm.worker, time.Second)
go wait.UntilWithContext(ctx, jm.orphanWorker, time.Second)
}
<-ctx.Done()
}2. worker() 方法和 processNextWorkItem() 方法#
由上述代码要点①处循环体可知,jm.worker() 方法会被 Run() 方法中启动的协程调用。在每个协程中,worker 方法每次退出 1 秒后会被再次启动,如此往复。worker() 方法内部直接调用 processNextWorkItem() 方法,该方法核心功能是从工作队列 queue 拿出一个待处理的 Job 实例的 key,然后启动控制循环的主逻辑——syncHandler 字段所指代的方法进行处理,如以下代码的要点①所示。 syncHandler 是基座结构体第一个字段,在构造控制器对象 时被指向 syncJob() 方法,所以控制器主逻辑实际是在 syncJob() 方法内。
// 代码: pkg\controller\job\job_controller.go#L634-L639
// worker runs a worker thread that just dequeues items, processes them, and marks them done.
// It enforces that the syncHandler is never invoked concurrently with the same key.
func (jm *Controller) worker(ctx context.Context) {
for jm.processNextWorkItem(ctx) {
}
}
func (jm *Controller) processNextWorkItem(ctx context.Context) bool {
key, quit := jm.queue.Get()
if quit {
return false
}
defer jm.queue.Done(key)
//要点①
err := jm.syncHandler(ctx, key)
if err == nil {
jm.queue.Forget(key)
return true
}
utilruntime.HandleError(fmt.Errorf("syncing job: %w", err))
jm.queue.AddRateLimited(key)
return true
}3. syncJob() 方法#
syncJob() 方法是控制循环的主逻辑,代码比较长不在这里全部罗列,简述一下其内部处理的过程。首先程序用传入的 Job key 在本地缓存中找到该 Job 实例,深拷贝从而生成一个新的 Job 资源实例,后续控制循环对 Job 信息的更新是在这个新实例上进行的,不能直接更新缓存中的资源实例。
接下来控制循环读取该 Job 的当前状态信息,例如上次成功运行了多少 Pod、失败了多少、上次循环后又有多少 Pod 成功和失败,从而得到最新数字。据此判断 Job 的当前状态:
- 如果 Job 完全符合完成要求,则更新 Job 状态并退出,这时它也从工作队列退出。
- 如果当前 Job 实例被暂停了,则把这个 Job 实例重新放入工作队列,等待下次控制循环的运行。
- 这个 Job 还没有运行完毕,控制循环计算还需要多少 Pod 去执行什么任务,并且指定其他参数,例如最大并行处理数。这部分工作是在方法
manageJob()中进行,在后面环节介绍。
以上处理均结束后,需要检验 Job 实例有关的 Pod,统计系统跑完的 Pod,决定是否符合结束条件,并将最新状态信息写回数据库。这些是在方法 trackJobStatusAndRemoveFinalizer() 中进行。
4. manageJob() 方法#
manageJob() 方法比较 Job 实例的目标和当前状态,从而作出操作。每个 API 的控制器都会有类似先比较再处理的逻辑,这部分代码是最具资源类型特色的。
对于 Job 资源来说,它主要的状态就是与其有关的 Pod 实例信息:多少 Pod 正在运行;最大可并行运行数量;共需运行多少次,与目标次数相比还需要跑几次。根据比较结果调整系统,向目标状态前进。方法核心代码如下所示:
// 代码: pkg\controller\job\job_controller.go#L1643-L1837
func (jm *Controller) manageJob(ctx context.Context, job *batch.Job, jobCtx *syncJobCtx) (int32, string, error) {
...
podsToDelete := activePodsForRemoval(job, jobCtx.activePods, int(rmAtLeast))
if len(podsToDelete) > MaxPodCreateDeletePerSync {
podsToDelete = podsToDelete[:MaxPodCreateDeletePerSync]
}
if len(podsToDelete) > 0 { //要点①
jm.expectations.ExpectDeletions(logger, jobKey, len(podsToDelete))
logger.V(4).Info("Too many pods running for job", "job", klog.KObj(job), "deleted", len(podsToDelete), "target", wantActive)
removedReady, removed, err := jm.deleteJobPods(ctx, job, jobKey, podsToDelete)
active -= removed
if trackTerminatingPods(job) {
*jobCtx.terminating += removed
}
jobCtx.ready -= removedReady
// While it is possible for a Job to require both pod creations and
// deletions at the same time (e.g. indexed Jobs with repeated indexes), we
// restrict ourselves to either just pod deletion or pod creation in any
// given sync cycle. Of these two, pod deletion takes precedence.
return active, metrics.JobSyncActionPodsDeleted, err
}
var terminating int32 = 0
if onlyReplaceFailedPods(jobCtx.job) {
// When onlyReplaceFailedPods=true, then also trackTerminatingPods=true,
// and so we can use the value.
terminating = *jobCtx.terminating
}
if diff := wantActive - terminating - active; diff > 0 { //要点②
var remainingTime time.Duration
if !hasBackoffLimitPerIndex(job) {
// we compute the global remaining time for pod creation when backoffLimitPerIndex is not used
remainingTime = jobCtx.newBackoffRecord.getRemainingTime(jm.clock, DefaultJobPodFailureBackOff, MaxJobPodFailureBackOff)
}
if remainingTime > 0 {
jm.enqueueSyncJobWithDelay(logger, job, remainingTime)
return 0, metrics.JobSyncActionPodsCreated, nil
}
if diff > int32(MaxPodCreateDeletePerSync) {
diff = int32(MaxPodCreateDeletePerSync)
}
var indexesToAdd []int
if isIndexedJob(job) {
indexesToAdd = firstPendingIndexes(jobCtx, int(diff), int(*job.Spec.Completions))
if hasBackoffLimitPerIndex(job) {
indexesToAdd, remainingTime = jm.getPodCreationInfoForIndependentIndexes(logger, indexesToAdd, jobCtx.podsWithDelayedDeletionPerIndex)
if remainingTime > 0 {
jm.enqueueSyncJobWithDelay(logger, job, remainingTime)
return 0, metrics.JobSyncActionPodsCreated, nil
}
}
diff = int32(len(indexesToAdd))
}
jm.expectations.ExpectCreations(logger, jobKey, int(diff))
errCh := make(chan error, diff)
logger.V(4).Info("Too few pods running", "key", jobKey, "need", wantActive, "creating", diff)
wait := sync.WaitGroup{}
active += diff
podTemplate := job.Spec.Template.DeepCopy()
if isIndexedJob(job) {
addCompletionIndexEnvVariables(podTemplate)
}
podTemplate.Finalizers = appendJobCompletionFinalizerIfNotFound(podTemplate.Finalizers)
...
}
...
}在上述代码中看到,比较的结果有两种可能:
- 目前运行次数超出了剩余运行次数,则程序需要停止一定数量的 Pod。这与代码中要点①对应。
- 目前运行次数没有达到要求的运行次数,则控制循环会为这个 Job 资源实例启动一定数目的 Pod。代码中要点②对应这种检测结果。
5. trackJobStatusAndRemoveFinalizer() 方法#
经过以上处理,控制器启动或关停了一些 Pod 满足该 Job 的期望,接下来对 Pod 的状态进行一次检验和再统计,统计结果会决定 Job 是否已完成工作。这些信息会作为状态写入 job.status 中。这里不再展开,请自行查阅源码。
通过这些控制器,Kubernetes 实现了声明式 API。内置 API 的控制器和客制化 API 的控制器共同构成控制器集合,支撑起 Kubernetes 系统的运转流程,前者 Kubernetes 项目开发,由控制面集中运行它们并监控其健康状况。客制化 API 的控制器由用户编程实现,对它们的监控同样需由用户实现。
扩展 Server 中控制器实现#
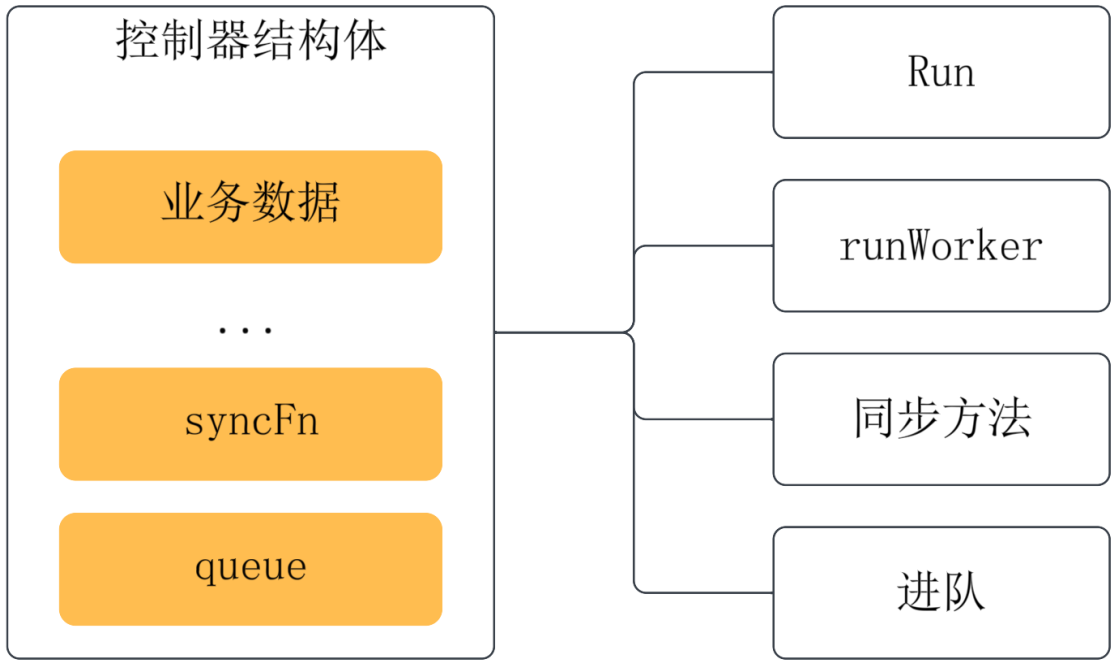
每个控制器均遵从上述所介绍的控制器设计模式,内部结构十分类似,这里可以总结一下:
- 首先,控制器以一个 Go 结构体为核心数据结构,称为基座结构体,该结构体内会包含一个工作队列(queue)用于记录增删改了的 API 实例,会有一个类型为方法的字段用于处理增删改,字段名一般为
syncFn; - 然后,以该结构体为接收者定义一系列方法。这些方法有的是控制器用方法:如
Run()来启动控制器,runWorker()启动控制循环,enqueueXXX()方法用来判断增删改的发生并将 API 实例放入队列;而有的代表当前控制器的主逻辑,用于处理 API 实例的增删改,可以称为同步方法,将被赋予控制器结构体的 syncFn 字段。同步方法是一个控制器的核心逻辑。
控制器核心元素如图所示。
发现控制器#
在 New() 函数中,提到两个发现器的 discovery 字段是必须填充的,这两个 map 把客制化 API 的组名(或组内版本名)映射到可以给出组(或版本)内容的结构体实例。填充它们并不简单。和 Kubernetes 内置 API 非常不同,客制化 API 可以是用户动态创建的,没有办法一次性找出所有客制化 API,而是要在 API Server 中出现新 CRD 或有 CRD 变更发生时采取行动,调整 discovery 属性内容。
此外,当聚合器响应针对端点 /apis 的 GET 请求时,会给出主 Server、扩展 Server 以及聚合 Server 所支持的所有 API 组,包括客制化 API 组,所以聚合器也需要及时获知 CRD 实例的增改删。这种运行时动态调整的操作特别适合用控制器模式去实现。扩展 Server 开发了发现控制器来服务于上述需求,发现控制器的基座结构体及其方法代码如下所示:
// 代码:
type DiscoveryController struct {
versionHandler *versionDiscoveryHandler
groupHandler *groupDiscoveryHandler
resourceManager discoveryendpoint.ResourceManager
crdLister listers.CustomResourceDefinitionLister
crdsSynced cache.InformerSynced
// To allow injection for testing.
syncFn func(version schema.GroupVersion) error
queue workqueue.TypedRateLimitingInterface[schema.GroupVersion]
}
func (c *DiscoveryController) sync(version schema.GroupVersion) error {
…
}
func (c *DiscoveryController) Run(stopCh <-chan struct{}, synchedCh chan<- struct{}) {
…
}
func (c *DiscoveryController) runWorker() {
…
}
func (c *DiscoveryController) processNextWorkItem() bool {
…
}
func (c *DiscoveryController) enqueue(obj *apiextensionsv1.CustomResourceDefinition) {
…
}
func (c *DiscoveryController) addCustomResourceDefinition(obj interface{}) {
…
}
func (c *DiscoveryController) updateCustomResourceDefinition(oldObj, newObj interface{}) {
…
}
func (c *DiscoveryController) deleteCustomResourceDefinition(obj interface{}) {
…
}发现控制器基座结构体的字段
versionHandler和groupHandler对应组和版本发现器- 发现控制器会填充它们的
discovery字段; resourceManager字段负责为聚合器提供所有客制化 API 组的信息;
- 发现控制器会填充它们的
crdLister用于获取 API Server 中所有的 CRD 实例;syncFn是一个方法,每一次控制循环发现有 CRD 的增改删,去执行的主要逻辑就在这里;queue是个队列,新创建、被修改的 CRD 实例会被放入其中等待在控制循环中去处理。NewDiscoveryController()可以创建一个发现控制器实例:// 代码: staging\src\k8s.io\apiextensions-apiserver\pkg\apiserver\customresource_discovery_controller.go#L61-89 func NewDiscoveryController( crdInformer informers.CustomResourceDefinitionInformer, versionHandler *versionDiscoveryHandler, groupHandler *groupDiscoveryHandler, resourceManager discoveryendpoint.ResourceManager, ) *DiscoveryController { c := &DiscoveryController{ versionHandler: versionHandler, groupHandler: groupHandler, resourceManager: resourceManager, crdLister: crdInformer.Lister(), crdsSynced: crdInformer.Informer().HasSynced, queue: workqueue.NewTypedRateLimitingQueueWithConfig( workqueue.DefaultTypedControllerRateLimiter[schema.GroupVersion](), workqueue.TypedRateLimitingQueueConfig[schema.GroupVersion]{Name: "DiscoveryController"}, ), } crdInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{ AddFunc: c.addCustomResourceDefinition, UpdateFunc: c.updateCustomResourceDefinition, DeleteFunc: c.deleteCustomResourceDefinition, }) c.syncFn = c.sync return c }上述代码展示了如下信息:
- 组发现器、版本发现器以及
resourceManager字段都是通过入参赋值的,它们会在控制循环中被不断填充。 crdLister被赋值为一个由CRD Informer所产生的Lister,Informer机制是客户端从API Server获取API实例的高效手段。- 工作队列被赋值为一个具有限流功能的队列,增改删的 CRD 的 Key 都会先放入其中。队列的填充实际上是由
crdInformer进行,它充当了“生产者”:要点①处的方法调 用告诉该Informer,当有增改删时分别去调用DiscoverController的addCustomResourceDefinition()、updateCustomResourceDefinition()和deleteCustomResourceDefition()方法。 - 而发现控制器的控制循环主逻辑方法——字段
syncFn被赋值为DiscoverController.sync()方法,读者了解清楚该方法的逻辑就清楚了该控制器的主逻辑。Sync()方法是工作队列的“消费者”。
- 组发现器、版本发现器以及
当控制循环发现 queue 中有待处理内容,就会逐个取出交给 sync() 方法去处理,sync() 负责填充组发现器、版本发现器和 resourceManager。
handler 填充#
versionDiscoveryHandler.discovery和groupDiscoveryHandler.discovery在被New()时是空的,之后由 DiscoveryController 在运行时动态填充的。// apiserver.go versionDiscoveryHandler := &versionDiscoveryHandler{ discovery: map[schema.GroupVersion]*discovery.APIVersionHandler{}, // 空 map delegate: delegateHandler, } groupDiscoveryHandler := &groupDiscoveryHandler{ discovery: map[string]*discovery.APIGroupHandler{}, // 空 map delegate: delegateHandler, } // 传入 DiscoveryController(传的是指针,共享同一个 map) discoveryController := NewDiscoveryController( s.Informers.Apiextensions().V1().CustomResourceDefinitions(), versionDiscoveryHandler, // 指针 groupDiscoveryHandler, // 指针 aggregatedDiscoveryManager, )创建
discoveryController时,使用versionDiscoveryHandler、groupDiscoveryHandler的指针。// customresource_discovery_controller.go func NewDiscoveryController(...) *DiscoveryController { c := &DiscoveryController{ versionHandler: versionHandler, // 保存指针 groupHandler: groupHandler, // 保存指针 ... } // 监听 CRD 的增删改事件 crdInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{ AddFunc: c.addCustomResourceDefinition, UpdateFunc: c.updateCustomResourceDefinition, DeleteFunc: c.deleteCustomResourceDefinition, }) return c }DiscoveryController 注册事件监听
// customresource_discovery_controller.go func NewDiscoveryController(...) *DiscoveryController { c := &DiscoveryController{ versionHandler: versionHandler, // 保存指针 groupHandler: groupHandler, // 保存指针 ... } // 监听 CRD 的增删改事件 crdInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{ AddFunc: c.addCustomResourceDefinition, UpdateFunc: c.updateCustomResourceDefinition, DeleteFunc: c.deleteCustomResourceDefinition, }) return c }CRD 变化时填充 discovery
// customresource_discovery_controller.go - sync() 方法 func (c *DiscoveryController) sync(version schema.GroupVersion) error { // ... 遍历所有 CRD,构建发现信息 ... // 填充 groupDiscoveryHandler.discovery c.groupHandler.setDiscovery(version.Group, discovery.NewAPIGroupHandler(Codecs, apiGroup)) // 填充 versionDiscoveryHandler.discovery c.versionHandler.setDiscovery(version, discovery.NewAPIVersionHandler(Codecs, version, ...)) }
时序图如下:
┌──────────────┐ ┌─────────────────────┐ ┌─────────────────────┐
│ apiserver │ │ DiscoveryController │ │ versionDiscovery │
│ New() │ │ │ │ Handler.discovery │
└──────┬───────┘ └──────────┬──────────┘ └──────────┬──────────┘
│ │ │
│ 创建空 map │ │
│──────────────────────────────────────────────────>│ {}
│ │ │
│ 传入指针 │ │
│──────────────────────>│ │
│ │ │
│ │ (Server 启动后) │
│ │ 监听到 CRD 创建 │
│ │ │
│ │ setDiscovery() │
│ │─────────────────────────>│ {gv: handler}
│ │ │
│ │ 监听到 CRD 删除 │
│ │ │
│ │ unsetDiscovery() │
│ │─────────────────────────>│ {}
——————————————————————————————————————————————————————————————————————————————————
New() 函数执行 Server 启动后
─────────────────────────────────────────────────────────────────────────>
│ │
│ 创建空的 handler │
│ 创建 crdHandler │
│ 注册路由 │
│ 创建 Controller(不运行) │
│ 注册 Hook(不执行) │
│ │
│ return s │ Hook 执行
│ │ Informer 启动
│ │ Controller 运行
│ │ 监听到 CRD
│ │ setDiscovery() 填充数据
│ │
▼ ▼
discovery = {} discovery = {gv: handler, ...}在 hasCRDInformerSyncedSignal 被 close 之前(即 Informer 同步完成前):
- 对 CR 端点的请求会返回 503 Service Unavailable
- 不会真正去查询空的 discovery map
503 保护范围如下:
┌─────────────────────────────────────────────────────────────────────────┐
│ Server 启动阶段 │
│ │
│ Informer 首次同步(List 所有已存在的 CRD) │
│ ↓ │
│ 这期间所有 CR 请求返回 503 │
│ ↓ │
│ 同步完成,close(hasCRDInformerSyncedSignal) │
│ ↓ │
│ Server 正常服务 │
└─────────────────────────────────────────────────────────────────────────┘
│
↓
┌─────────────────────────────────────────────────────────────────────────┐
│ Server 运行阶段 │
│ │
│ 用户创建新 CRD │
│ ↓ │
│ Informer Watch 到事件 │
│ ↓ │
│ DiscoveryController 调用 setDiscovery() │
│ ↓ │
│ 这期间如果访问该 CRD 的 CR → 返回 404(不是 503) │
│ ↓ │
│ 填充完成后正常访问 │
└─────────────────────────────────────────────────────────────────────────┘名称控制器#
客制化 API 会有名字,包括单数名称、复数名称、短名称;也会有种类(kind)和 ListKind 信息。名字在 CRD 实例内定义,系统需要检查这些名称是否在同组内出现冲突。例如同组、同种类只应出现在单一 CRD 实例中。检查工作由名称控制器完成。名称控制器的基座结构体定义如下代码所示:
// 代码: staging\src\k8s.io\apiextensions-apiserver\pkg\controller\status\naming_controller.go#L48-L62
// This controller is reserving names. To avoid conflicts, be sure to run only one instance of the worker at a time.
// This could eventually be lifted, but starting simple.
type NamingConditionController struct {
crdClient client.CustomResourceDefinitionsGetter
crdLister listers.CustomResourceDefinitionLister
crdSynced cache.InformerSynced
// crdMutationCache backs our lister and keeps track of committed updates to avoid racy
// write/lookup cycles. It's got 100 slots by default, so it unlikely to overrun
// TODO to revisit this if naming conflicts are found to occur in the wild
crdMutationCache cache.MutationCache
// To allow injection for testing.
syncFn func(key string) error
queue workqueue.TypedRateLimitingInterface[string]
}控制器的检验结果需要写回 API 实例的 Status,这里 crdClient 属性用来执行写回。syncFn 属性被赋值为该结构体的 sync() 方法,这个方法的内部逻辑是比较冲突是否存在,记录合法的名字等信息,并根据冲突状态设置 CRD 实例的 conditon,并写回 CRD 实例。
非结构化规格控制器#
CRD 实例会针对其定义的客制化 API 所具有的字段和属性进行规格定义,例如类型是整数还是字符串,长度限制等。而 CRD 实例是用户使用资源定义文件写出来的,对规格的表述是否符合 OpenAPI Schema 的语法定义很有必要验证。这项任务由非结构化规格控制器来完成。
1. 校验逻辑#
本控制器核心的逻辑自然是如何做规格校验,其实现在 calculateCondition() 函数
// 代码: staging\src\k8s.io\apiextensions-apiserver\pkg\controller\nonstructuralschema\nonstructuralschema_controller.go#L88-L133
func calculateCondition(in *apiextensionsv1.CustomResourceDefinition) *apiextensionsv1.CustomResourceDefinitionCondition {
cond := &apiextensionsv1.CustomResourceDefinitionCondition{
Type: apiextensionsv1.NonStructuralSchema,
Status: apiextensionsv1.ConditionUnknown,
}
allErrs := field.ErrorList{}
if in.Spec.PreserveUnknownFields {
allErrs = append(allErrs, field.Invalid(field.NewPath("spec", "preserveUnknownFields"),
in.Spec.PreserveUnknownFields,
fmt.Sprint("must be false")))
}
for i, v := range in.Spec.Versions {
if v.Schema == nil || v.Schema.OpenAPIV3Schema == nil {
continue
}
internalSchema := &apiextensionsinternal.CustomResourceValidation{}
if err := apiextensionsv1.Convert_v1_CustomResourceValidation_To_apiextensions_CustomResourceValidation(v.Schema, internalSchema, nil); err != nil {
klog.Errorf("failed to convert CRD validation to internal version: %v", err)
continue
}
s, err := schema.NewStructural(internalSchema.OpenAPIV3Schema)
if err != nil {
cond.Reason = "StructuralError"
cond.Message = fmt.Sprintf("failed to check validation schema for version %s: %v", v.Name, err)
return cond
}
pth := field.NewPath("spec", "versions").Index(i).Child("schema", "openAPIV3Schema")
allErrs = append(allErrs, schema.ValidateStructural(pth, s)...)
}
if len(allErrs) == 0 {
return nil
}
cond.Status = apiextensionsv1.ConditionTrue
cond.Reason = "Violations"
cond.Message = allErrs.ToAggregate().Error()
return cond
}该方法接收一个 CRD 为入参,然后对这个 CRD 中定义的客制化 API 的版本列表进行循环,均做如下几步:
将该版本的 schema 内容(类型为结构体
CustomResourceValidation)从当前版本转化为内部版本。用以内部版本表示的 Schema 制作结构化规格(structural schema),结构化规格的类型是 Structural,它的定义如下:
// 代码: staging\src\k8s.io\apiextensions-apiserver\pkg\apiserver\schema\structural.go#L27-L37 // Structural represents a structural schema. type Structural struct { Items *Structural Properties map[string]Structural AdditionalProperties *StructuralOrBool Generic Extensions ValidationExtensions ValueValidation *ValueValidation }如果制作结构化规则失败,意味着 CRD 实例的资源定义文件有违规,不必进行下去,整个方法直接返回错误。
针对上一步制作出的结构化规格,调用如下方法进行校验并记录下发现的错误,该方法源代码如下:
func ValidateStructural(fldPath *field.Path, s *Structural) field.ErrorList { return ValidateStructuralWithOptions(fldPath, s, ValidationOptions{ // This would widen the schema for CRD if set to true, so first few releases will still // not admit any. But it can still be used by libraries and // declarative validation for native types AllowNestedAdditionalProperties: false, AllowNestedXValidations: false, AllowValidationPropertiesWithAdditionalProperties: false, }) }上述循环执行完毕后,如果任何一个版本有检验失败,该方法就返回一个
CustomResourceDefinitionCondition结构体实例,其内记录错误情况;而如果没有失败发生,将返回 nil。
2. sync() 方法#
本控制器的 syncFn 字段被赋值为方法 sync(),它针对 CRD 实例的增删改调用上述规格校验逻辑。其内部执行逻辑如下:
- 取出目标 CRD 实例。
- 调用上述
calculateCondition()函数,计算校验结果,得到CustomResourceDefinitionCondition,这代表 CRD 实例最新的非结构化规格状态。 - 获取 CRD 实例的 Status 中类型是
NonStructuralSchema的 condition 信息,这代表了之前 CRD 实例的非结构化规格状态。 - 比较(2)与(3)的两个状态,如果不一致,更新之;让 Status 中类型是
NonStructuralSchema的 condition 为最新状态。
API 审批控制器#
2019 年,Kubernetes 的 Github 库中出现一项提议:社区应该着手在 CRD 领域保护属于社区的 API 组,这些组要么名为 k8s.io、kubernetes.io,要么是以之结尾,符合 *.k8s.io 和 *.kubernetes.io 模式。
保护的方式是这样:如果在 CRD 中定义客制化 API 使用的组名符合上述模式,则代表要在 kubernetes 专有组内进行新 API 创建,这需要经社区审批,作者要在该 API 上通过注解给出审批通过的 pull request,例如:
"api-approved.kubernetes.io": "https://github.com/kubernetes/kubernetes/pull/78458"如果由于某些原因暂时还没有获批,但依然需要创建,则需要在该注解上使用 “unapproved”开头的文字。API 审批控制器就是针对这条规则对一个 CRD 实例进行校验。校验的结果会反映到 CRD 实例的 Status 上。
1. 校验逻辑#
理解了本控制器的目的后再看校验逻辑就很简单了:如果目标 CRD 实例正在向 Kubernetes 专有组中引入新 API,拿到该 CRD 实例的注解 api-approved.kubernetes.io,看是否合规,据此形成 condition 返回。这正是方法 calculateCondition() 所做的事情,其代码如下所示:
// calculateCondition determines the new KubernetesAPIApprovalPolicyConformant condition
func calculateCondition(crd *apiextensionsv1.CustomResourceDefinition) *apiextensionsv1.CustomResourceDefinitionCondition {
if !apihelpers.IsProtectedCommunityGroup(crd.Spec.Group) {
return nil
}
approvalState, reason := apihelpers.GetAPIApprovalState(crd.Annotations)
switch approvalState {
case apihelpers.APIApprovalInvalid:
return &apiextensionsv1.CustomResourceDefinitionCondition{
Type: apiextensionsv1.KubernetesAPIApprovalPolicyConformant,
Status: apiextensionsv1.ConditionFalse,
Reason: "InvalidAnnotation",
Message: reason,
}
case apihelpers.APIApprovalMissing:
return &apiextensionsv1.CustomResourceDefinitionCondition{
Type: apiextensionsv1.KubernetesAPIApprovalPolicyConformant,
Status: apiextensionsv1.ConditionFalse,
Reason: "MissingAnnotation",
Message: reason,
}
case apihelpers.APIApproved:
return &apiextensionsv1.CustomResourceDefinitionCondition{
Type: apiextensionsv1.KubernetesAPIApprovalPolicyConformant,
Status: apiextensionsv1.ConditionTrue,
Reason: "ApprovedAnnotation",
Message: reason,
}
case apihelpers.APIApprovalBypassed:
return &apiextensionsv1.CustomResourceDefinitionCondition{
Type: apiextensionsv1.KubernetesAPIApprovalPolicyConformant,
Status: apiextensionsv1.ConditionFalse,
Reason: "UnapprovedAnnotation",
Message: reason,
}
default:
return &apiextensionsv1.CustomResourceDefinitionCondition{
Type: apiextensionsv1.KubernetesAPIApprovalPolicyConformant,
Status: apiextensionsv1.ConditionUnknown,
Reason: "UnknownAnnotation",
Message: reason,
}
}
}2. sync() 方法#
完全类似非结构化规格控制器的 sync() 方法,甚至连计算 condition 的方法都同名,这里不再赘述。Sync() 方法的最终执行结果要么是更新名为 KubernetesAPIApprovalPolicyConformant 的 condition,要么是什么都不做。
CRD 清理控制器#
如果一个 CRD 实例被删除,则依附其上的客制化资源同样应该被删除,皮之不存毛将焉附嘛。本控制器就是做客制化资源的删除清理的。
下面提及的方法均在源文件
staging\src\k8s.io\apiextensions-apiserver\pkg\controller\finalizer\crd_finalizer.go中。
1. 删除客制化资源的逻辑#
方法 deleteInstances() 包含了客制化资源的删除逻辑,它的执行过程如下:
- 找到目标 CRD 实例的所有客制化资源;
- 以命名空间为单位,逐个清理其中的目标客制化资源;
- 以 5 秒为间隔检查清理的状态,看否全部清理完毕,最长等一分钟;
- 返回清理状态,如果有错误连同错误一起返回。
本方法返回一个类型为 CustomResourceDefinitionCondition 的状态,用于标识删除结果。
2. sync() 方法#
当有 CRD 实例被删除时,本方法被调用来进行清理操作。它会调用 deleteInstances() 方法,然后把该方法返回的 condition 写回被删除 CRD 实例的 Status 中;接着移除 CRD 实例上的名为 customresourcecleanup.apiextensions.k8s.io 的 Finalizer,确保系统可以删除 CRD 实例。
