K8s Aggregation Server#
下面将进入核心API Server 的最后一块拼图——聚合器以及扩展 API Server 的另一种途径——聚合 Server。作为 API Server 链的头,聚合器和 Server 链上其它子 Server 一样,也是以 Generic Server 为底座构建的
背景与目的#
在引入并在 API Server 上实现了 CRD 后,社区对 API Server 扩展的需求得以释放,大量的 Kubernetes 解决方案开始使用 CRD 机制制作客制化 API。时至今日这一做法依然是扩展 API Server 的主流方式。也许是 CRD 打开了人们的想象空间,越来越多的公司、项目和专家期望通过引入 API 来扩展 Kubernetes 的能力,并且渐渐不再满足 CRD 这种模仿内置 API 的方式,而是希望引入地道的 Kubernetes API。开发者首先想到的是引入新的内置 API。结果是 Github 上积压了大量需要去 Review 的关于新 API 的代码提交,根本没有足够的力量及时审核。即使人力不是问题,绝大部分提交也会被拒绝,因为这些期望被引入的 API 并不具备足够的普遍性。此路不通,需要另寻他途。
2017 年 8 月,一份通过创建聚合 Server 来引入新 API 的增强建议被提了出来,最终这份提议通过了评审被正式采纳。它的核心思想是把原本单体的 API Server 改装成由多个子 Server 构成的集合,有一点儿微服务化的意思。提出了两个目标:
- 每个 Developer 都可以通过自建子 Server(称为聚合 Server)的方式来向集群引入新的客制化 API。
- 这些新 API 应该无缝扩展内置 API,就是说它们与内置 API 相比无明显使用差别。
这一提议最终确立了当今 API Server 的整体架构,主 Server、扩展 Server、第三方自主开发的聚合 Server 以及将它们连为一体的聚合器共同构成了当今控制面上的 API Server,它们分管不同 API 并提供请求处理器处理来自客户端的请求。引入聚合器是为了能协调和管理这些子 Server,聚合器起到三方面作用:
- 提供一个 Kubernetes API,供子 Server 注册自己所支持的 API。
- 汇集发现信息(Discovery)。简单来说就是收集子 Server 所支持的 API Group 和 Version,供外界通过
/apis端点来直接获取,这样当查询请求到来时就不必去询问各子 Server 了。发现信息的典型消费者包括kubectl和控制器管理器。拿控制器管理器来说,它需要查询集群具有的 API,从而决定哪些控制器需要启动而哪些不必。 - 做一个反向代理,把客户端来的请求转发到聚合 Server 上去。
为了让每个开发者都可以高效创建聚合 Server,Kubernetes 的 Generic Server 库被构造得足够易用。
通过前面的学习,已充分了解了 Generic Server,也明白主 Server、扩展 Server 如何在其基础上构建,对 Generic Server 的可重用性应该有了充分认识。每个开发者都可以依葫芦画瓢,用 Generic Server 创建自己的聚合 Server。从工具的角度来讲,Kubernetes 社区也提供了众多脚手架。这方面的成果有很多,例如 Kubernetes SIG 开发的 API Server Builder 就专业做聚合 Server 开发。
API Server 结构#
API Server 结构图如下:
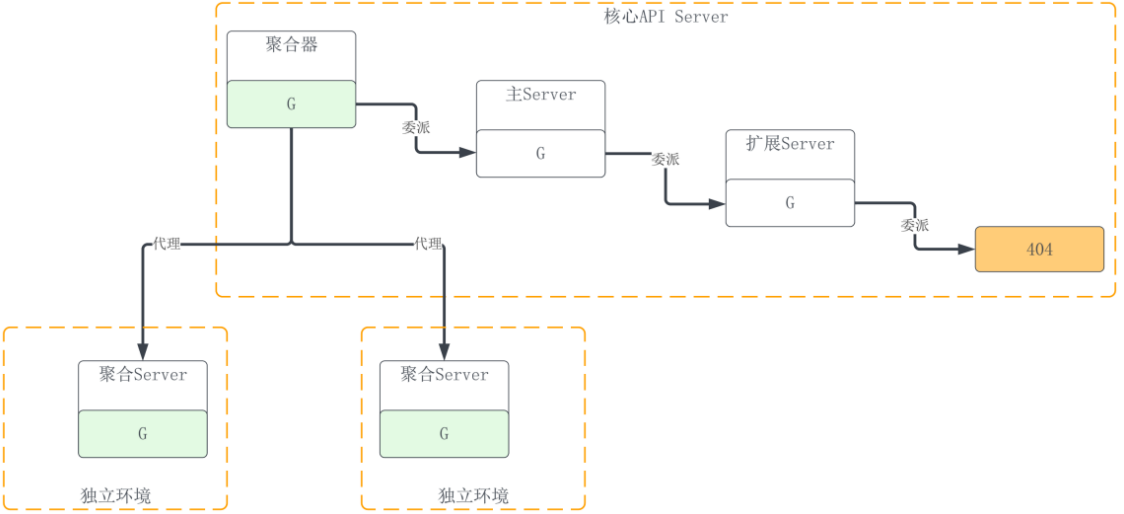
它显示聚合 Server 与其它子 Server 的地位明显不同。虽然核心 Server 中的聚合器、主 Server 和扩展 Server 都基于 Generic Server 独立构建,也可以编译成单独应用程序独立运行,但在 Kubernetes API Server 的实现中它们被放入一个应用程序,即核心 API Server。而聚合 Server 则不同,一般来说每一个聚合 Server 都是一个独立 的 Web Server,独立运行于核心 API Server 之外。
核心 API Server#
常说的 “启动控制面上的 API Server” 实际指启动核心 API Server,它是一个可执行程序。当编译 Kubernetes 工程时可以生成所有组件,这是一系列可执行程序,核心 API Server 就是其中之一。它内部包含了聚合器、主 Server 和扩展 Server 所支持的所有内置 API,能处理客户端发送给各个子 Server 的 HTTP 请求。主 Server 和扩展 Server 均基于 Generic Server 并且具有成为独立可执行程序的能力,但当它们和聚合器一起构成核心API Server 时它们之间并没有独立,核心 API Server 对三者的整合如下图所示:
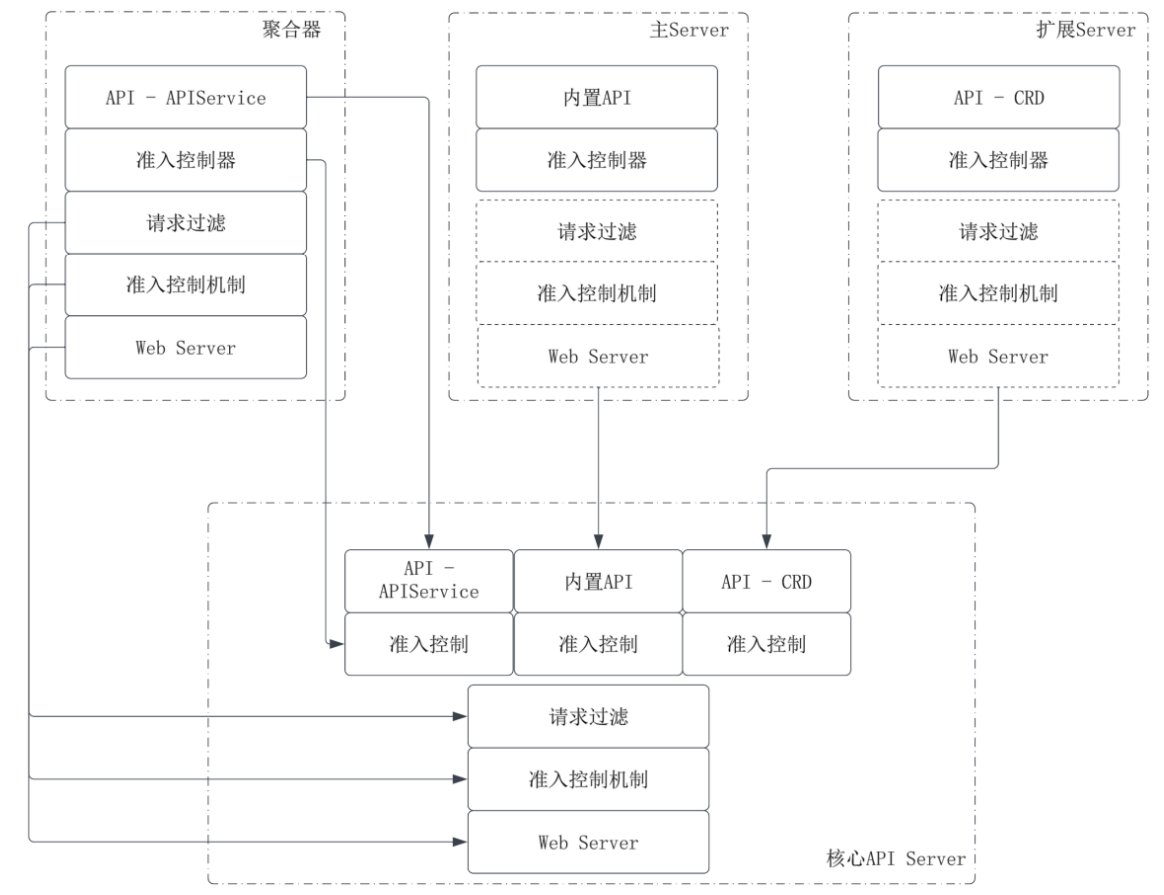
选取有代表性的几个方面来展示核心 API Server 的构成方式,这些方面是:所支持的 API、准入控制器、请求过滤、准入控制机制和底层 Web Server 的基本能力。这里忽略了其它方面,例如和各自 API 密切相关的控制器、启动后关闭前的钩子函数。
- 底层 Web Server,准入控制机制和请求过滤的能力来自聚合器底座 Generic Server。
- 只有 Aggregator(聚合器) 的底层能力(Web Server、请求过滤、准入机制)被真正启动和使用。
- Master Server 和 Extension Server 中原本自带的 Web Server 和过滤器逻辑(图中上半部分的虚线框)被旁路/忽略了。它们的代码还在那里(物理存在),但运行时不会通过它们接收外部 TCP 请求(逻辑不存在)。
- 因为一个进程只需要监听一个端口(通常是 6443),不需要启动三个 HTTP 服务器。聚合器作为最外层,启用的是聚合器的 HTTP Server,所以接管了网络监听,而 Master Server 和 Extension Server 的 HTTP 没有启动,所以只是逻辑存在。
- 所支持 API 是聚合器、主 Server 和扩展 Server 所支持 API 的合集。
- API 路由:聚合器的路由 + 核心资源的路由 + CRD 的路由,全部注册到同一个 HTTP 路由器中。
- 准入控制机制含有三个子 Server 的准入控制器合集。
- 准入控制器 (Admission Controllers):三个 Server 各自需要的准入逻辑(比如检查 Pod 规范的、检查 CRD 格式的)都会被加载进来,形成一个完整的准入控制链。
这种组合是一种逻辑上而非物理上的组合,主 Server 和扩展 Server 中没有被采用的部分依然存在,只是它们永远也不会被系统调用到,最典型的就是它们的底座 Generic Server 的 Web 服务器被弃置不用。这当然是代码上的冗余,却带来工程上的巨大便利。
API Server 整体结构#
现在把聚合 Server 也考虑进来,API Server 将构成如图所示的结构:
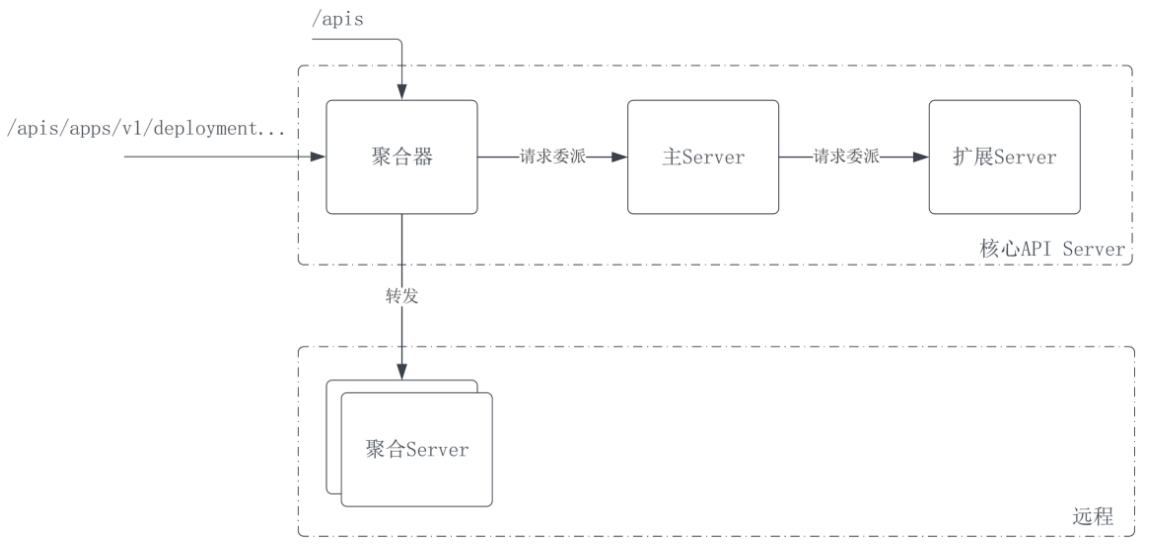
核心 API Server 中各个子 Server 同处于一个可执行程序内,它们构成了前文提及的 Server 链。当一个针对 Kubernetes API 的请求到来时,聚合器先行判断出正确的响应子 Server,然后采取不同处理方式:
- 那些针对 API APIService 的请求被聚合器自身响应。
- 如果是主 Server 或扩展 Server 的 API,则直接将请求委派给自己手中握有的 Delegation 就好了,该 Delegation 实际上是主 Server 的引用。拿到请求后主 Server 一样会判断是否归自己处理,不是的话也会交给它的 Delegation——扩展 Server。
- 如果是某个聚合 Server,则通过自己的代理功能,将请求发送给目标 Server,等待结果。
聚合器和聚合 Server 之间由网络连接,一种常见的做法是让聚合 Server 跑在当前集群内的某个 Pod 内,此时处于控制面的聚合器通过集群内网和该 Server 交互。交互过程中聚合器启用了自己的代理(Proxy)能力。
聚合器的一个能力是收集各个子 Server 的发现信息,据此直接响应针对“/apis”的 Get 请求。这个请求的含义是询问 API Server 它所支持的所有 API Group 以及 Version 信息。一种简单的做法是当有请求来时去遍历子 Server,索要这一信息并返回给客户端;而聚合器则是事先从子 Server 获取然后保存在自己的缓存中,从而加速响应效率。由于 CRD 和聚合 Server 的存在,Group 和 Version 不是静态不变的,例如新的 CRD 的创建或新的聚合 Server 的加入都会带来新的 Group 和 Version,为了及时更新自己的缓存,聚合器引入了控制器,聚合器后续会详细介绍。
这里来详细总结一下聚合 Server 作为整个 Kubernetes 集群 API 流量的第一入口,他的核心作用可以概括为如下三点:
- 统一入口与分流;
- 内部请求委派;
- 外部扩展转发。
