Mutex 的基本使用#
Locker 接口#
在 Go 的标准库中,package sync 提供了锁相关的一系列同步原语,这个 package 还定义了一个 Locker 的接口,Mutex 就实现了这个接口。
Locker 的接口定义了锁同步原语的方法集:
type Locker interface {
Lock()
Unlock()
}Go 定义的锁接口的方法集很简单,就是请求锁(Lock)和释放锁(Unlock)这两个方法。但在实际中,我们一般会直接使用具体的同步原语,而不是通过接口。
Mutex 和 RWMutex 都实现了 Locker 接口。
Mutex#
互斥锁 Mutex 就提供两个方法 Lock 和 Unlock:进入临界区之前调用 Lock 方法,退出临界区的时候调用 Unlock 方法:
func(m *Mutex)Lock()
func(m *Mutex)Unlock()当一个 goroutine 通过调用 Lock 方法获得了这个锁的拥有权后, 其它请求锁的 goroutine 就会阻塞在 Lock 方法的调用上,直到锁被释放并且自己获取到了这个锁的拥有权。
使用场景#
例如:我们创建了 10 个 goroutine,同时不断地对一个变量(count)进行加 1 操作,每个 goroutine 负责执行 10 万次的加 1 操作,我们期望的最后计数的结果是 10 * 100000 = 1000000 (一百万)
import (
"fmt"
"sync"
)
func main() {
var count = 0
// 使用WaitGroup等待10个goroutine完成
var wg sync.WaitGroup
wg.Add(10)
for i := 0; i < 10; i++ {
go func() {
defer wg.Done()
// 对变量count执行10次加1
for j := 0; j < 100000; j++ {
count++
}
}()
}
// 等待10个goroutine完成
wg.Wait()
fmt.Println(count)
}使用 sync.WaitGroup 来等待所有的 goroutine 执行完毕后,再输出最终的结果。每次运行,你都可能得到不同的结果,基本上不会得到理想中的一百万的结果。
$ go run counter.go
855347
$ go run counter.go
802752
$ go run counter.go
789473这是因为,count++ 不是一个原子操作,它至少包含几个步骤,比如读取变量 count 的当前值,对这个值加 1,把结果再保存到 count 中。因为不是原子操作,就可能有并发的问题。
比如,10 个 goroutine 同时读取到 count 的值为 9527,接着各自按照自己的逻辑加 1,值变成了 9528,然后把这个结果再写回到 count 变量。但是,实际上,此时我们增加的总数应该是 10 才对,这里却只增加了 1,好多计数都被“吞”掉了。这是并发访问共享数据的常见错误。
针对这个问题:Go 提供了一个检测并发访问共享资源是否有问题的工具:race detector,它可以帮助我们自动发现程序有没有 data race 的问题。
在编译(compile)、测试(test)或者运行(run)Go 代码的时候,加上 race 参数,就有可能发现并发问题。比如在上面的例子中,我们可以加上 race 参数运行,检测一下是不是有并发问题。如果你 go run -race counter.go,就会输出警告信息。
$ go run -race counter.go
==================
WARNING: DATA RACE
Read at 0x00c00009a078 by goroutine 14:
main.main.func1()
/home/going/golang/src/github.com/LiangNing7/conc/mutex/1.1counter/counter.go:19 +0x99
Previous write at 0x00c00009a078 by goroutine 7:
main.main.func1()
/home/going/golang/src/github.com/LiangNing7/conc/mutex/1.1counter/counter.go:19 +0xab
Goroutine 14 (running) created at:
main.main()
/home/going/golang/src/github.com/LiangNing7/conc/mutex/1.1counter/counter.go:15 +0x84
Goroutine 7 (running) created at:
main.main()
/home/going/golang/src/github.com/LiangNing7/conc/mutex/1.1counter/counter.go:15 +0x84
==================
==================
WARNING: DATA RACE
Write at 0x00c00009a078 by goroutine 14:
main.main.func1()
/home/going/golang/src/github.com/LiangNing7/conc/mutex/1.1counter/counter.go:19 +0xab
Previous write at 0x00c00009a078 by goroutine 7:
main.main.func1()
/home/going/golang/src/github.com/LiangNing7/conc/mutex/1.1counter/counter.go:19 +0xab
Goroutine 14 (running) created at:
main.main()
/home/going/golang/src/github.com/LiangNing7/conc/mutex/1.1counter/counter.go:15 +0x84
Goroutine 7 (running) created at:
main.main()
/home/going/golang/src/github.com/LiangNing7/conc/mutex/1.1counter/counter.go:15 +0x84
==================
850860
Found 2 data race(s)
exit status 66这个警告不但会告诉你有并发问题,而且还会告诉你哪个 goroutine 在哪一行对哪个变量有写操作,同时,哪个 goroutine 在哪一行对哪个变量有读操作,就是这些并发的读写访问,引起了 data race。
虽然这个工具使用起来很方便,但是,因为它的实现方式,只能通过真正对实际地址进行读写访问的时候才能探测,所以它并不能在编译的时候发现 data race 的问题。而且,在运行的时候,只有在触发了 data race 之后,才能检测到,如果碰巧没有触发(比如一个 data race 问题只能在 2 月 14 号零点或者 11 月 11 号零点才出现),是检测不出来的。
而且,把开启了 race 的程序部署在线上,还是比较影响性能的。
这个工具的实现机制:通过在编译的时候插入一些指令,在运行时通过这些插入的指令检测并发读写从而发现 data race 问题。
这里的共享资源是 count 变量,临界区是 count++,只要在临界区前面获取锁,在离开临界区的时候释放锁,就能完美地解决 data race 的问题了。
package main
import (
"fmt"
"sync"
)
func main() {
var mu sync.Mutex
count := 0
// 使用 WaitGroup 等待 10 个 goroutine 完成.
var wg sync.WaitGroup
wg.Add(10)
for i := 0; i < 10; i++ {
go func() {
defer wg.Done()
// 对变量进行执行 100000 次加 1.
for j := 0; j < 100000; j++ {
mu.Lock()
count++
mu.Unlock()
}
}()
}
// 等待 10 个 goroutine 完成.
wg.Wait()
fmt.Println(count)
}如果你再运行一下程序,就会发现,data race 警告没有了,系统干脆地输出了 1000000。
这里有一点需要注意:Mutex 的零值是还没有 goroutine 等待的未加锁的状态,所以你不需要额外的初始化,直接声明变量(如 var mu sync.Mutex)即可。
这样,就可以通过将 Mutex 嵌入到其他 struct 中使用。
type Counter struct {
mu sync.Mutex
Count uint64
}在初始化嵌入的 struct 时,也不必初始化这个 Mutex 字段,不会因为没有初始化出现空指针或者是无法获取到锁的情况。
有时候,我们还可以采用嵌入字段的方式。通过嵌入字段,你可以在这个 struct 上直接调用 Lock/Unlock 方法。
type Counter struct {
sync.Mutex
Count uint64
}
func main() {
var counter Counter
var wg sync.WaitGroup
wg.Add(10)
for i := 0; i < 10; i++ {
go func() {
defer wg.Done()
for j := 0; j < 100000; j++ {
counter.Lock()
counter.Count++
counter.Unlock()
}
}()
}
wg.Wait()
fmt.Println(counter.Count)
}如果嵌入的 struct 有多个字段,我们一般会把 Mutex 放在要控制的字段上面,然后使用空格把字段分隔开来。即使你不这样做,代码也可以正常编译,只不过,用这种风格去写的话,逻辑会更清晰,也更易于维护。
还可以把获取锁、释放锁、计数加一的逻辑封装成一个方法,对外不需要暴露锁等逻辑:
func main() {
// 封装好的计数器
var counter Counter
var wg sync.WaitGroup
wg.Add(10)
// 启动10个goroutine
for i := 0; i < 10; i++ {
go func() {
defer wg.Done()
// 执行10万次累加
for j := 0; j < 100000; j++ {
counter.Incr() // 受到锁保护的方法
}
}()
}
wg.Wait()
fmt.Println(counter.Count())
}
// 线程安全的计数器类型
type Counter struct {
CounterType int
Name string
mu sync.Mutex
count uint64
}
// 加1的方法,内部使用互斥锁保护
func (c *Counter) Incr() {
c.mu.Lock()
c.count++
c.mu.Unlock()
}
// 得到计数器的值,也需要锁保护
func (c *Counter) Count() uint64 {
c.mu.Lock()
defer c.mu.Unlock()
return c.count
}Mutex 的进化史#
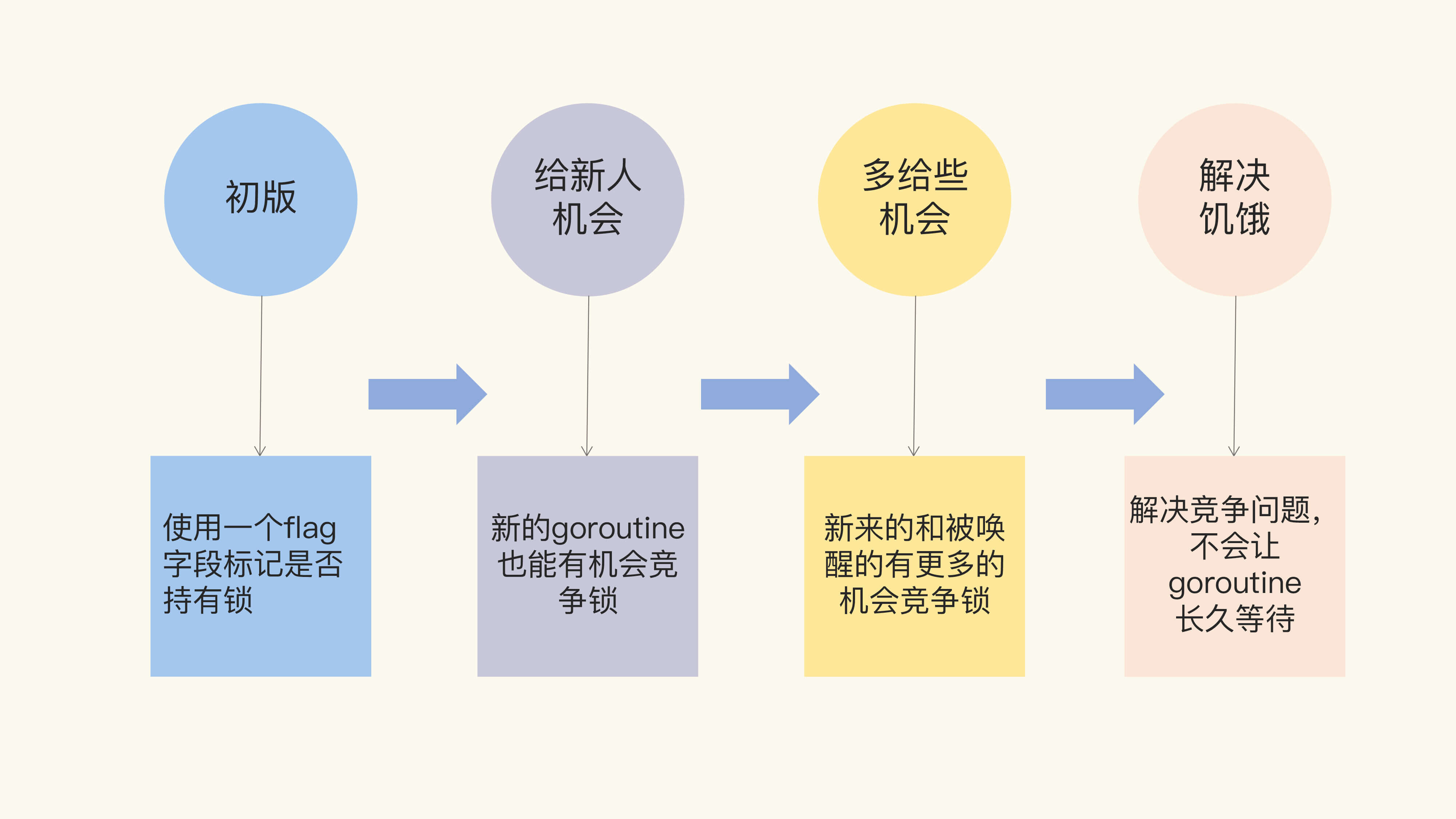
Mutex 的架构演进分成了四个阶段,下面给你画了一张图来说明。
- “初版” 的 Mutex 使用一个 flag 来表示锁是否被持有,实现比较简单;
- 后来照顾到新来的 goroutine,所以会让新的 goroutine 也尽可能地先获取到锁,这是第二个阶段,我把它叫作“给新人机会”;
- 那么,接下来就是第三阶段“多给些机会”,照顾新来的和被唤醒的 goroutine;
- 但是这样会带来饥饿问题,所以目前又加入了饥饿的解决方案,也就是第四阶段“解决饥饿”。
初版的 mutex#
通过一个 flag 变量,标记当前的锁是否被某个 goroutine 持有。如果这个 flag 的值是 1,就代表锁已经被持有,那么,其它竞争的 goroutine 只能等待;如果这个 flag 的值是 0,就可以通过 CAS(compare-and-swap,或者 compare-and-set)【CAS操作,但是没有抽象出 atomic 包】将这个 flag 设置为 1,标识锁被当前的这个 goroutine 持有了。
// CAS操作,当时还没有抽象出atomic包
func cas(val *int32, old, new int32) bool
func semacquire(*int32)
func semrelease(*int32)
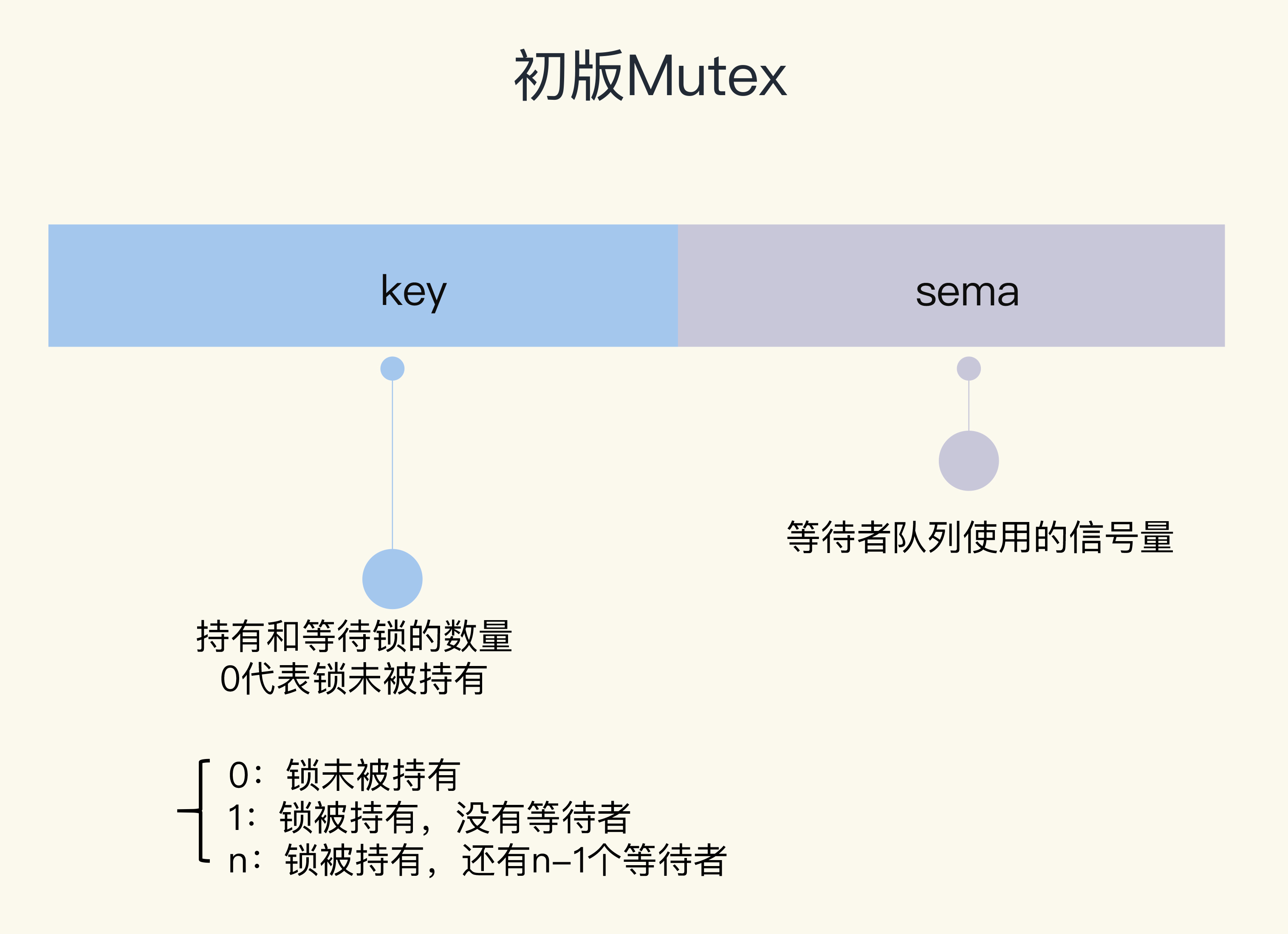
// 互斥锁的结构,包含两个字段
type Mutex struct {
key int32 // 锁是否被持有的标识
sema int32 // 信号量专用,用以阻塞/唤醒goroutine
}
// 保证成功在 val 上增加 delta 的值
func xadd(val *int32, delta int32) (new int32) {
for {
v := *val
if cas(val, v, v+delta) {
return v + delta
}
}
panic("unreached")
}
// 请求锁
func (m *Mutex) Lock() {
if xadd(&m.key, 1) == 1 { // 标识加1,如果等于1,成功获取到锁
return
}
semacquire(&m.sema) // 否则阻塞等待
}
func (m *Mutex) Unlock() {
if xadd(&m.key, -1) == 0 { // 将标识减去1,如果等于0,则没有其它等待者
return
}
semrelease(&m.sema) // 唤醒其它阻塞的goroutine
}CAS 指令将给定的值和一个内存地址中的值进行比较,如果它们是同一个值,就使用新值替换内存地址中的值,并且这个操作是原子性的,原子性保证这个指令总是基于最新的值进行计算,如果同时有其它线程已经修改了这个值,那么,CAS 会返回失败。CAS 是实现互斥锁和同步原语的基础。
Mutex 结构体包含两个字段:
- 字段
key:是一个 flag,用来标识这个排外锁是否被某个 goroutine 所持有,如果 key 大于等于 1,说明这个排外锁已经被持有; - 字段
sema:是个信号量变量,用来控制等待 goroutine 的阻塞休眠和唤醒。 - 考虑:为何不就只使用 key 来管理?key 用于快路径+计数,sema 用于慢路径,要把 Goroutine 挂起。挂起和唤醒涉及到复杂的调度逻辑,成本很高。
sema就是专门为这种“重负载”操作提供挂载点的。
调用 Lock 请求锁的时候,通过 xadd 方法进行 CAS 操作(第 24 行),xadd 方法通过循环执行 CAS 操作直到成功,保证对 key 加 1 的操作成功完成。如果比较幸运,锁没有被别的 goroutine 持有,那么,Lock 方法成功地将 key 设置为 1,这个 goroutine 就持有了这个锁;如果锁已经被别的 goroutine 持有了,那么,当前的 goroutine 会把 key 加 1,而且还会调用 semacquire 方法(第 27 行),使用信号量将自己休眠,等锁释放的时候,信号量会将它唤醒。
持有锁的 goroutine 调用 Unlock 释放锁时,它会将 key 减 1(第 31 行)。如果当前没有其它等待这个锁的 goroutine,这个方法就返回了。但是,如果还有等待此锁的其它 goroutine,那么,它会调用 semrelease 方法(第 34 行),利用信号量唤醒等待锁的其它 goroutine 中的一个。
初版的 Mutex 利用 CAS 原子操作,对 key 这个标志量进行设置。key 不仅仅标识了锁是否被 goroutine 所持有,还记录了当前持有和等待获取锁的 goroutine 的数量。
Unlock 方法可以被任意的 goroutine 调用释放锁,即使是没持有这个互斥锁的 goroutine,也可以进行这个操作。这是因为,Mutex 本身并没有包含持有这把锁的 goroutine 的信息,所以,Unlock 也不会对此进行检查。Mutex 的这个设计一直保持至今。
示例:
package main import ( "fmt" "sync" ) func main() { var mu sync.Mutex var wg sync.WaitGroup done := make(chan struct{}) wg.Add(1) // A goroutine 加锁并执行工作. go func() { mu.Lock() fmt.Println("Goroutine A: 资源已锁定") // 在这里完成一些操作... // 然后通知另一 goroutine 进行解锁. done <- struct{}{} }() // B goroutine 等待通知后解锁. go func() { <-done mu.Unlock() fmt.Println("Goroutine B: 资源已解锁") wg.Done() // 演示完成. }() // 等待演示完成. wg.Wait() }运行结果:
$ go run main.go Goroutine A: 资源已锁定 Goroutine B: 资源已解锁
这就带来了一个有趣而危险的功能。其它 goroutine 可以强制释放锁,这是一个非常危险的操作,因为在临界区的 goroutine 可能不知道锁已经被释放了,还会继续执行临界区的业务操作,这可能会带来意想不到的结果,因为这个 goroutine 还以为自己持有锁呢,有可能导致 data race 问题。
我们在使用 Mutex 的时候,必须要保证 goroutine 尽可能不去释放自己未持有的锁,一定要遵循 “谁申请,谁释放” 的原则。在真实的实践中,我们使用互斥锁的时候,很少在一个方法中单独申请锁,而在另外一个方法中单独释放锁,一般都会在同一个方法中获取锁和释放锁。并且Go 对 defer 做了优化,采用更有效的内联方式,取代之前的生成 defer 对象到 defer chain 中,defer 对耗时的影响微乎其微了,这样就可以让 Lock/Unlock 总是成对紧凑出现,不会遗漏或者多调用,代码更少。
func (f *Foo) Bar() {
f.mu.Lock()
defer f.mu.Unlock()
if f.count < 1000 {
f.count += 3
return
}
f.count++
return
}问题:
初版的 Mutex 实现有一个问题:请求锁的 goroutine 会排队等待获取互斥锁。虽然这貌似很公平,但是从性能上来看,却不是最优的。因为如果我们能够把锁交给正在占用 CPU 时间片的 goroutine 的话,那就不需要做上下文的切换,在高并发的情况下,可能会有更好的性能。
给新人机会#
NOTE:
更加倾向给正在占用 CPU 时间片的 goroutine,减少上下文切换带来的开销。
Go 开发者在 2011 年 6 月 30 日的 commit 中对 Mutex 做了一次大的调整,调整后的 Mutex 实现如下:
type Mutex struct {
state int32
sema uint32
}
const (
mutexLocked = 1 << iota // mutex is locked
mutexWoken
mutexWaiterShift = iota
)这里补一下 iota 的操作:
遇
const归零: 每当源码中出现const关键字时,iota的值就会被重置为0。按行递增: 在
const块中,每新增一行常量声明,iota的值就会自动加1。隐式继承: 如果在常量声明中省略了等号和表达式,它会默认复制上一行的表达式,但会使用当前行最新的
iota值去计算。mutexLocked:此时 iota = 0;1 « 0 = 1;
mutexWoken:此时 iota = 1;且继承上一行表达式,1 « 1 = 2;
mutexWaiterShift:此时 iota = 2;声明为 iota,即 2。
虽然 Mutex 结构体还是包含两个字段,但是第一个字段已经改成了 state,它的含义也不一样了。
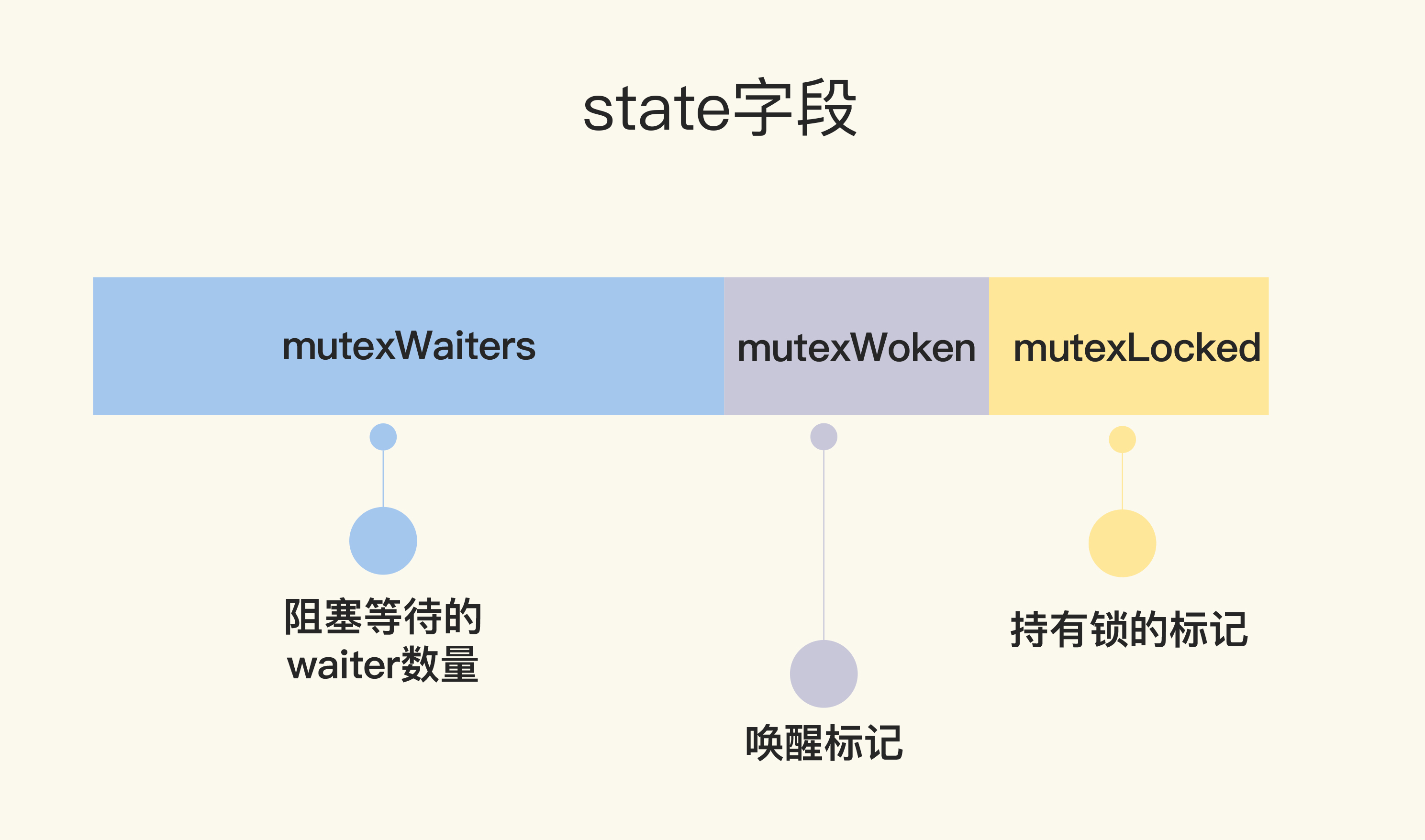
state 是一个复合型的字段,一个字段包含多个意义,这样可以通过尽可能少的内存来实现互斥锁。这个字段的第一位(最小的一位)来表示这个锁是否被持有,第二位代表是否有唤醒的 goroutine,剩余的位数代表的是等待此锁的 goroutine 数。所以,state 这一个字段被分成了三部分,代表三个数据。
mutexWaiters:表示阻塞等待的 waiter 数量;mutexWoken:用于表示当前是否有被唤醒的 goroutine 正在尝试获取锁;mutexLocked:用于表示当前是否有 goroutine 持有该锁。
获取锁#
请求锁的方法 Lock 也变得复杂了。复杂之处不仅仅在于对字段 state 的操作难以理解,而且代码逻辑也变得相当复杂。
func (m *Mutex) Lock() {
// Fast path: 幸运 case,能够直接获取到锁
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
return
}
awoke := false // 每个 goroutine 的局部变量
for {
old := m.state
new := old | mutexLocked // 新状态加锁,默认都设置「想要持有锁」标志
if old&mutexLocked != 0 {
new = old + 1<<mutexWaiterShift // 等待者数量加一
}
if awoke {
// 如果是从 runtime.Semacquire 被唤醒的 goroutine(awoke == true)
// 就要去掉 mutexWoken,让下一个等待者可以被唤醒。
new &^= mutexWoken
}
if atomic.CompareAndSwapInt32(&m.state, old, new) { // 设置新状态,这里成功设置,不代表抢到了锁
if old & mutexLocked == 0 { // 锁原状态未加锁,说明抢到了锁
break
}
runtime.Semacquire(&m.sema) // 锁仍被占用,自己要阻塞在信号量上
awoke = true
}
}
}首先是通过 CAS 检测 state 字段中的标志(第 3 行)
func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool)
addr:指向int32变量的指针,表示需要操作的内存地址。
old:预期的旧值,用于比较。
new:如果比较成功,将设置的新值。
swapped:布尔值,表示是否成功交换。工作原理:
- 原子性检查:函数会原子地检查
addr指向的当前值是否等于old。- 条件交换:
- 如果当前值等于
old,则将addr的值设置为new,并返回true。- 否则,不进行任何操作,直接返回
false。
检查 state 是否为 0,state 为 0 则表示:
- 锁未被持有(
mutexLocked位为 0); - 没有等待的协程被唤醒(
mutexWoken位为 0); - 没有协程在等待(
mutexWaiterShift部分为 0。
这样当前的 goroutine 就很幸运,可以直接获得锁,这也是注释中的 Fast path 的意思。
如果不够幸运,即第 3 行代码的 CAS 失败,state 不是零值,说明有持有者,那么就通过一个循环进行检查。其整理逻辑为:如果想要获取锁的 goroutine 没有机会获取到锁,就会进行休眠,但是在锁释放唤醒之后,它并不能像先前一样直接获取到锁,还是要和正在请求锁的 goroutine 进行竞争。这会给后来请求锁的 goroutine 一个机会,也让 CPU 中正在执行的 goroutine 有更多的机会获取到锁,在一定程度上提高了程序的性能。
for 循环是不断尝试获取锁,如果获取不到,就通过 runtime.Semacquire(&m.sema) 休眠,休眠醒来之后 awoke 置为 true,尝试争抢锁。
代码中的第 10 行将当前的 flag 设置为加锁状态,如果能成功地通过 CAS 把这个新值赋予 state(第 19 行和第 20 行),就代表抢夺锁的操作成功了。
不过,需要注意的是,如果成功地设置了 state 的值,但是之前的 state 是有锁的状态,那么,state 只是清除 mutexWoken 标志或者增加一个 waiter 而已。
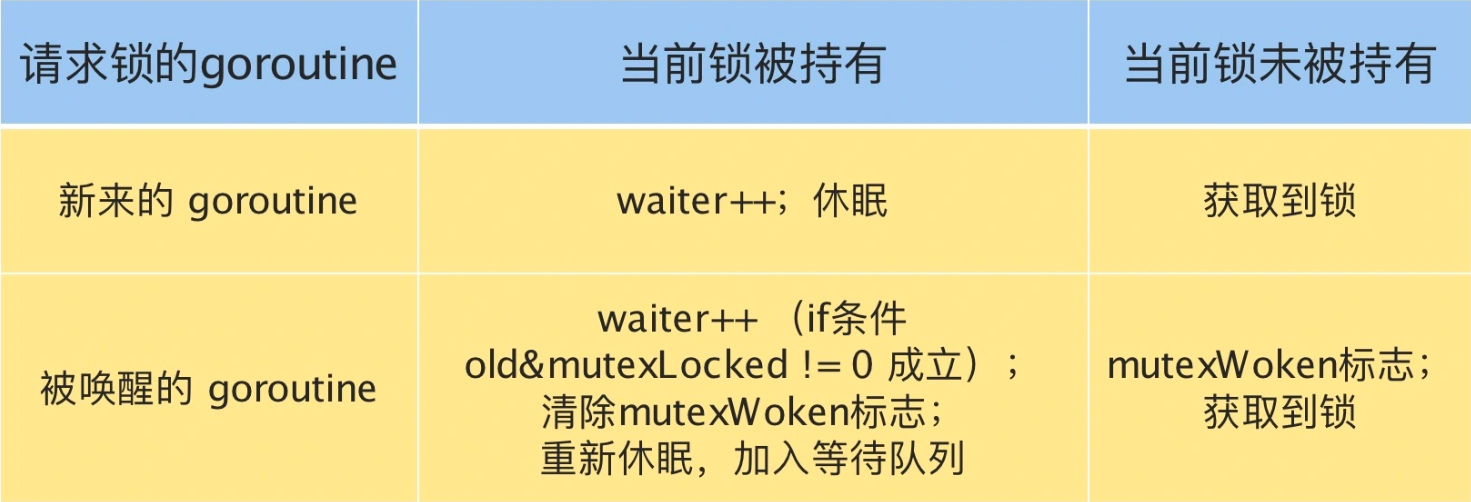
请求锁的 goroutine 有两类,一类是新来请求锁的 goroutine,另一类是被唤醒的等待请求锁的 goroutine。锁的状态也有两种:加锁和未加锁。
释放锁#
释放锁的 Unlock 方法也有些复杂,我们来看一下。
func (m *Mutex) Unlock() {
// Fast path: drop lock bit.
new := atomic.AddInt32(&m.state, -mutexLocked) // 去掉锁标志
if (new+mutexLocked)&mutexLocked == 0 { // 本来就没有加锁
panic("sync: unlock of unlocked mutex")
}
old := new
for {
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken) != 0 { // 没有等待者,或者有唤醒的waiter,或者锁原来已加锁
return
}
new = (old - 1<<mutexWaiterShift) | mutexWoken // 新状态,准备唤醒goroutine,并设置唤醒标志
if atomic.CompareAndSwapInt32(&m.state, old, new) {
runtime.Semrelease(&m.sema)
return
}
old = m.state
}
}第 3 行是尝试将持有锁的标识设置为未加锁的状态,这是通过减 1 而不是将标志位置零的方式实现。第 4 到 6 行还会检测原来锁的状态是否已经未加锁的状态,如果是 Unlock 一个未加锁的 Mutex 会直接 panic。
不过,即使将加锁置为未加锁的状态,这个方法也不能直接返回,还需要一些额外的操作,因为还可能有一些等待这个锁的 goroutine(有时候我也把它们称之为 waiter)需要通过信号量的方式唤醒它们中的一个。所以接下来的逻辑有两种情况。
第一种情况,如果没有其它的 waiter,说明对这个锁的竞争的 goroutine 只有一个,那就可以直接返回了;如果这个时候有唤醒的 goroutine,或者是又被别人加了锁,那么,无需我们操劳,其它 goroutine 自己干得都很好,当前的这个 goroutine 就可以放心返回了。
第二种情况,如果有等待者,并且没有唤醒的 waiter,那就需要唤醒一个等待的 waiter。在唤醒之前,需要将 waiter 数量减 1,并且将 mutexWoken 标志设置上,这样,Unlock 就可以返回了。通过这样复杂的检查、判断和设置,我们就可以安全地将一把互斥锁释放了。
相对于初版的设计,这次的改动主要就是,新来的 goroutine 也有机会先获取到锁,甚至一个 goroutine 可能连续获取到锁,打破了先来先得的逻辑。但是,代码复杂度也显而易见。
虽然这一版的 Mutex 已经给新来请求锁的 goroutine 一些机会,让它参与竞争,没有空闲的锁或者竞争失败才加入到等待队列中。
多给些机会#
在 2015 年 2 月的改动中,如果新来的 goroutine 或者是被唤醒的 goroutine 首次获取不到锁,它们就会通过自旋(spin,通过循环不断尝试,spin 的逻辑是在 runtime 实现的)的方式,尝试检查锁是否被释放。在尝试一定的自旋次数后,再执行原来的逻辑。
func (m *Mutex) Lock() {
// Fast path: 幸运之路,正好获取到锁
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
return
}
awoke := false
iter := 0
for { // 不管是新来的请求锁的goroutine, 还是被唤醒的goroutine,都不断尝试请求锁
old := m.state // 先保存当前锁的状态
new := old | mutexLocked // 新状态设置加锁标志
if old&mutexLocked != 0 { // 锁还没被释放
if runtime_canSpin(iter) { // 还可以自旋
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&
atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
awoke = true
}
runtime_doSpin()
iter++
continue // 自旋,再次尝试请求锁
}
new = old + 1<<mutexWaiterShift
}
if awoke { // 唤醒状态
if new&mutexWoken == 0 {
panic("sync: inconsistent mutex state")
}
new &^= mutexWoken // 新状态清除唤醒标记
}
if atomic.CompareAndSwapInt32(&m.state, old, new) {
if old&mutexLocked == 0 { // 旧状态锁已释放,新状态成功持有了锁,直接返回
break
}
runtime_Semacquire(&m.sema) // 阻塞等待
awoke = true // 被唤醒
iter = 0
}
}
}这次的优化,增加了第 13 行到 21 行、第 25 行到第 27 行以及第 36 行。
自旋优化(第13-21行)
if runtime_canSpin(iter) { // 还可以自旋
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&
atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
awoke = true
}
runtime_doSpin()
iter++
continue // 自旋,再次尝试请求锁
}通过自旋减少上下文切换的开销。
逻辑:
- 条件检查:
!awoke,当前 goroutine 尚未被唤醒;old&mutexWoken == 0,没有其他 goroutine 被唤醒;old>>mutexWaiterShift != 0,存在其他等待锁的 goroutine;atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken),将mutexWoken标记置为 1,通知解锁的 goroutine:“已有自旋中的 goroutine 准备获取锁,无需唤醒其他等待者”。
- 自旋操作:
- 调用
runtime_doSpin()执行自旋(占用CPU时间片,忙等待),而非立即休眠。 - 自旋次数
iter递增,当超过阈值后,停止自旋。
- 调用
唤醒状态校验(第25-27行)
if new&mutexWoken == 0 {
panic("sync: inconsistent mutex state")
}为什么要新增唤醒状态校验?
- 若
mutexWoken未被设置,说明该唤醒是无效的(例如锁状态已被其他 goroutine 篡改),此时直接panic暴露问题。
如果当前 goroutine 是被唤醒的(awoke == true),但新状态 new 中未包含 mutexWoken 标记,说明存在逻辑错误,触发 panic。
重置状态(第 36 行)
目的:重置 iter = 0,为下一次可能的自旋做准备。
自旋优化,这个对于临界区代码执行非常短的场景来说,这是一个非常好的优化。因为临界区的代码耗时很短,锁很快就能释放,而抢夺锁的 goroutine 不用通过休眠唤醒方式等待调度,直接 spin 几次,可能就获得了锁。
解决饥饿#
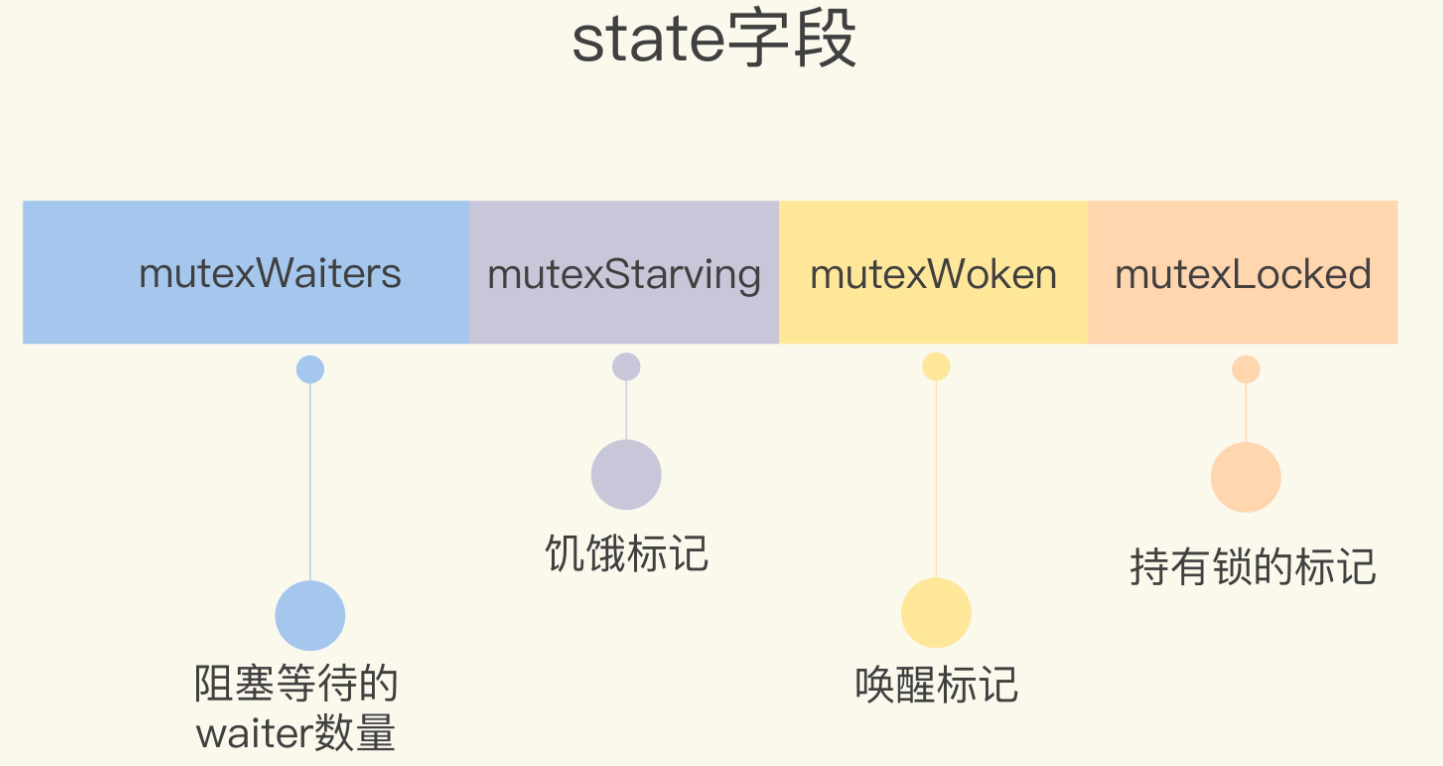
现在的 state 字段:
type Mutex struct {
state int32
sema uint32
}
const (
mutexLocked = 1 << iota // mutex is locked
mutexWoken
mutexStarving // 从 state 字段中分出一个饥饿标记
mutexWaiterShift = iota
starvationThresholdNs = 1e6
)
func (m *Mutex) Lock() {
// Fast path: 幸运之路,一下就获取到了锁
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
return
}
// Slow path:缓慢之路,尝试自旋竞争或饥饿状态下饥饿goroutine竞争
m.lockSlow()
}
func (m *Mutex) lockSlow() {
var waitStartTime int64
starving := false // 此goroutine的饥饿标记
awoke := false // 唤醒标记
iter := 0 // 自旋次数
old := m.state // 当前的锁的状态
for {
// 锁是非饥饿状态,锁还没被释放,尝试自旋
if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) {
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&
atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
awoke = true
}
runtime_doSpin()
iter++
old = m.state // 再次获取锁的状态,之后会检查是否锁被释放了
continue
}
new := old
if old&mutexStarving == 0 {
new |= mutexLocked // 非饥饿状态,加锁
}
if old&(mutexLocked|mutexStarving) != 0 {
new += 1 << mutexWaiterShift // waiter数量加1
}
if starving && old&mutexLocked != 0 {
new |= mutexStarving // 设置饥饿状态
}
if awoke {
if new&mutexWoken == 0 {
throw("sync: inconsistent mutex state")
}
new &^= mutexWoken // 新状态清除唤醒标记
}
// 成功设置新状态
if atomic.CompareAndSwapInt32(&m.state, old, new) {
// 原来锁的状态已释放,并且不是饥饿状态,正常请求到了锁,返回
if old&(mutexLocked|mutexStarving) == 0 {
break // locked the mutex with CAS
}
// 处理饥饿状态
// 如果以前就在队列里面,加入到队列头
queueLifo := waitStartTime != 0
if waitStartTime == 0 {
waitStartTime = runtime_nanotime()
}
// 阻塞等待
runtime_SemacquireMutex(&m.sema, queueLifo, 1)
// 唤醒之后检查锁是否应该处于饥饿状态
starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs
old = m.state
// 如果锁已经处于饥饿状态,直接抢到锁,返回
if old&mutexStarving != 0 {
if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 {
throw("sync: inconsistent mutex state")
}
// 有点绕,加锁并且将waiter数减1
delta := int32(mutexLocked - 1<<mutexWaiterShift)
if !starving || old>>mutexWaiterShift == 1 {
delta -= mutexStarving // 最后一个waiter或者已经不饥饿了,清除饥饿标记
}
atomic.AddInt32(&m.state, delta)
break
}
awoke = true
iter = 0
} else {
old = m.state
}
}
}
func (m *Mutex) Unlock() {
// Fast path: drop lock bit.
new := atomic.AddInt32(&m.state, -mutexLocked)
if new != 0 {
m.unlockSlow(new)
}
}
func (m *Mutex) unlockSlow(new int32) {
if (new+mutexLocked)&mutexLocked == 0 {
throw("sync: unlock of unlocked mutex")
}
if new&mutexStarving == 0 {
old := new
for {
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 {
return
}
new = (old - 1<<mutexWaiterShift) | mutexWoken
if atomic.CompareAndSwapInt32(&m.state, old, new) {
runtime_Semrelease(&m.sema, false, 1)
return
}
old = m.state
}
} else {
runtime_Semrelease(&m.sema, true, 1)
}
}跟之前的实现相比,当前的 Mutex 最重要的变化,就是增加饥饿模式。
第 12 行代码 starvationThresholdNs = 1e6 将饥饿模式的最大等待时间阈值设置成了 1 毫秒,这就意味着,一旦等待者等待的时间超过了这个阈值,Mutex 的处理就有可能进入饥饿模式,优先让等待者先获取到锁,新来的同学主动谦让一下,给老同志一些机会。
通过加入饥饿模式,可以避免把机会全都留给新来的 goroutine,保证了请求锁的 goroutine 获取锁的公平性,对于我们使用锁的业务代码来说,不会有业务一直等待锁不被处理。
正常模式和饥饿模式的比较#
Mutex 可能处于两种操作模式下:正常模式和饥饿模式。
请求锁时调用的 Lock 方法中一开始是 fast path,这是一个幸运的场景,当前的 goroutine 幸运地获得了锁,没有竞争,直接返回,否则就进入了 lockSlow 方法。这样的设计,方便编译器对 Lock 方法进行内联,你也可以在程序开发中应用这个技巧。
正常模式下,waiter 都是进入先入先出队列,被唤醒的 waiter 并不会直接持有锁,而是要和新来的 goroutine 进行竞争。新来的 goroutine 有先天的优势,它们正在 CPU 中运行,可能它们的数量还不少,所以,在高并发情况下,被唤醒的 waiter 可能比较悲剧地获取不到锁,这时,它会被插入到队列的前面。如果 waiter 获取不到锁的时间超过阈值 1 毫秒,那么,这个 Mutex 就进入到了饥饿模式。
在饥饿模式下,Mutex 的拥有者将直接把锁交给队列最前面的 waiter。新来的 goroutine 不会尝试获取锁,即使看起来锁没有被持有,它也不会去抢,也不会 spin,它会乖乖地加入到等待队列的尾部。
如果拥有 Mutex 的 waiter 发现下面两种情况的其中之一,它就会把这个 Mutex 转换成正常模式:
- 此 waiter 已经是队列中的最后一个 waiter 了,没有其它的等待锁的 goroutine 了;
- 此 waiter 的等待时间小于 1 毫秒。
正常模式拥有更好的性能,因为即使有等待抢锁的 waiter,goroutine 也可以连续多次获取到锁。
饥饿模式是对公平性和性能的一种平衡,它避免了某些 goroutine 长时间的等待锁。在饥饿模式下,优先对待的是那些一直在等待的 waiter。
饥饿模式详细分析#
接下来,我们逐步分析下 Mutex 代码的关键行,彻底搞清楚饥饿模式的细节。

第 9 行对 state 字段又分出了一位,用来标记锁是否处于饥饿状态。现在一个 state 的字段被划分成了阻塞等待的 waiter 数量、饥饿标记、唤醒标记和持有锁的标记四个部分。

第 25 行记录此 goroutine 请求锁的初始时间,第 26 行标记是否处于饥饿状态,第 27 行标记是否是被唤醒的,第 28 行变量 iter 记录 spin 的次数。

第 31 行到第 40 行和以前的逻辑类似,只不过加了一个不能是饥饿状态的逻辑,增加部分为:
if old&(mutexLocked|mutexStarving) == mutexLocked ...可以分解为:
old & mutexLocked == mutexLocked // 锁被占用
&&
old & mutexStarving == mutexLocked // 处于饥饿它会对正常状态抢夺锁的 goroutine 尝试 spin,和以前的目的一样,就是在临界区耗时很短的情况下提高性能。

第 42 行到第 44 行,非饥饿状态下抢锁。怎么抢?就是要把 state 的锁的那一位,置为加锁状态,后续 CAS 如果成功就可能获取到了锁。

第 46 行到第 48 行,如果锁已经被持有或者锁处于饥饿状态,我们最好的归宿就是等待,所以 waiter 的数量加 1。

第 49 行到第 51 行,如果此 goroutine 已经处在饥饿状态,并且锁还被持有,那么,我们需要把此 Mutex 设置为饥饿状态。

第 52 行到第 57 行,是清除 mutexWoken 标记,因为不管是获得了锁还是进入休眠,我们都需要清除 mutexWoken 标记。

第 59 行就是尝试使用 CAS 设置 state。

如果成功,第 61 行到第 63 行是检查原来的锁的状态是未加锁状态,并且也不是饥饿状态的话就成功获取了锁,返回。

第 67 行判断是否第一次加入到 waiter 队列。到这里,你应 该就能明白第 25 行为什么不对 waitStartTime 进行初始化了,我们需要利用它在这里进行条件判断。
第 72 行将此 waiter 加入到队列,如果是首次,加入到队尾,先进先出。如果不是首次,那么加入到队首,这样等待最久的 goroutine 优先能够获取到锁。此 goroutine 会进行休眠。

第 74 行判断此 goroutine 是否处于饥饿状态。注意,执行这一句的时候,它已经被唤醒了,因为不被唤醒,就会一直阻塞在第 72 行代码。

第 77 行到第 88 行是对锁处于饥饿状态下的一些处理。
if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 {
throw("sync: inconsistent mutex state")
}第 78 行代码检查非法状态,主要检查:锁是否已被占用、是否存在唤醒标记、等待者数量是否为 0
delta := int32(mutexLocked - 1<<mutexWaiterShift)第 82 行,有点绕,对其操作分解
mutexLocked:设置锁为“已占用”状态(例如0x1);-1<<mutexWaiterShift:将等待者数量减 1。
示例:假设 mutexWaiterShift 为 3:
delta = 0x1 - 8(即0x1表示加锁,-8表示等待者减 1);- 最终
delta的二进制为0x1 - 0x8 = -7(十进制)。
if !starving || old>>mutexWaiterShift == 1 {
delta -= mutexStarving // 最后一个waiter或者已经不饥饿了,清除饥饿标记
}第 83 - 85 行,设置标志,在没有其它的 waiter 或者此 goroutine 等待还没超过 1 毫秒,则会将 Mutex 转为正常状态。
atomic.AddInt32(&m.state, delta)
break第 86 - 87 行则是将这个标识应用到 state 字段上。并退出循环。
释放锁#
释放锁(Unlock)时调用的 Unlock 的 fast path 代码量较少且逻辑简单(通过原子操作快速释放锁),所以我们主要看 unlockSlow 方法就行。

如果 Mutex 处于饥饿状态,第 123 行直接唤醒等待队列中的 waiter。

如果 Mutex 处于正常状态,如果没有 waiter,或者已经有在处理的情况了,那么释放就好,不做额外的处理(第 112 行到第 114 行)。

否则,waiter 数减 1,mutexWoken 标志设置上,通过 CAS 更新 state 的值(第 115 行到第 119 行)。
思考题:等待一个 mutex 的 goroutine 数最大数量#
单从程序来看,可以支持 1 << (32 - 3) - 1 ,约 0.5Billion 个
其中 32 为 state 的类型 int32,3 位 waiter 字段的 shift,考虑到实际 goroutine 初始化的空间为2K,0.5Billin*2K 达到了 1TB,单从内存空间来说已经要求极高了。
Mutex 易错场景#
Lock / Unlock 不是成对出现#
缺少 Unlock 的场景,常见的有三种情况:
- 代码中有太多的 if-else 分支,可能在某个分支中漏写了 Unlock;
- 在重构的时候把 Unlock 给删除了;
- Unlock 误写成了 Lock。
缺少 Lock 的场景,这就很简单了,一般来说就是误操作删除了 Lock。这样直接 Unlock 一个为加锁的 Mutex 会 panic。
综上,我们在可以在 Lock() 之后直接调用 defer Unlock()
func foo() {
var mu sync.Mutex
mu.Lock()
defer mu.Unlock()
fmt.Println("hello world!")
}Copy 已使用的 Mutex#
Package sync 的同步原语在使用后是不能复制的。Mutex 是一个有状态的对象,它的 state 字段记录这个锁的状态。如果你要复制一个已经加锁的 Mutex 给一个新的变量,那么新的刚初始化的变量居然被加锁了,这显然不符合你的期望,因为你期望的是一个零值的 Mutex。关键是在并发环境下,你根本不知道要复制的 Mutex 状态是什么,因为要复制的 Mutex 是由其它 goroutine 并发访问的,状态可能总是在变化。
例如:
package main
import (
"fmt"
"sync"
)
type Counter struct {
sync.Mutex
Count int
}
func main() {
var c Counter
c.Lock()
defer c.Unlock()
c.Count++
foo(c)
}
// 这里 Counter 的参数是通过复制的方式传入的.
func foo(c Counter) {
c.Lock()
defer c.Unlock()
fmt.Println("in foo")
}第 18 行在调用 foo 函数的时候,调用者会复制 Mutex 变量 c 作为 foo 函数的参数,不幸的是,复制之前已经使用了这个锁,这就导致,复制的 Counter 是一个带状态 Counter。
如果是因为这样的原因导致的死锁问题,可以使用 vet 工具,把检查写在 Makefile 文件中,在持续集成的时候跑一跑,这样可以及时发现问题,及时修复。我们可以使用 go vet 检查这个 Go 文件:
$ go vet copy.go
# command-line-arguments
# [command-line-arguments]
./copy.go:18:6: call of foo copies lock value: command-line-arguments.Counter
./copy.go:22:12: foo passes lock by value: command-line-arguments.Countervet 工具是通过 copylock 分析器静态分析实现的。这个分析器会分析函数调用、range 遍历、复制、声明、函数返回值等位置,有没有锁的值 copy 的情景,以此来判断有没有问题。可以说,只要是实现了 Locker 接口,就会被分析。我们看到,下面的代码就是确定什么类型会被分析,其实就是实现了 Lock/Unlock 两个方法的 Locker 接口:
var lockerType *types.Interface
// Construct a sync.Locker interface type.
func init() {
nullary := types.NewSignature(nil, nil, nil, false) // func()
methods := []*types.Func{
types.NewFunc(token.NoPos, nil, "Lock", nullary),
types.NewFunc(token.NoPos, nil, "Unlock", nullary),
}
lockerType = types.NewInterface(methods, nil).Complete()
}其实,有些没有实现 Locker 接口的同步原语(比如 WaitGroup),也能被分析。
重入#
重入锁:当一个线程获取锁时,如果没有其它线程拥有这个锁,那么,这个线程就成功获取到这个锁。之后,如果其它线程再请求这个锁,就会处于阻塞等待的状态。但是,如果拥有这把锁的线程再请求这把锁的话,不会阻塞,而是成功返回,所以叫可重入锁(有时候也叫做递归锁)。只要你拥有这把锁,你可以可着劲儿地调用,比如通过递归实现一些算法,调用者不会阻塞或者死锁。
需要注意的是:Mutex 不是可重入锁,想想也不奇怪,因为 Mutex 的实现中没有记录哪个 goroutine 拥有这把锁。理论上,任何 goroutine 都可以随意地 Unlock 这把锁,所以没办法计算重入条件。
看一个重入 Mutex 的例子:
package main
import (
"fmt"
"sync"
)
func foo(l sync.Locker) {
fmt.Println("in foo")
l.Lock()
bar(l)
l.Unlock()
}
func bar(l sync.Locker) {
l.Lock()
fmt.Println("in bar")
l.Unlock()
}
func main() {
l := &sync.Mutex{}
foo(l)
}写完这个 Mutex 重入的例子后,运行一下,你会发现类似下面的错误。程序一直在请求锁,但是一直没有办法获取到锁,结果就是 Go 运行时发现死锁了,没有其它地方能够释放锁让程序运行下去,你通过下面的错误堆栈信息就能定位到哪一行阻塞请求锁:
$ go run ReentrantLock.go
in foo
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [sync.Mutex.Lock]:
internal/sync.runtime_SemacquireMutex(0xc000078e60?, 0xa?, 0x559660?)
/home/going/go/go1.24.0/src/runtime/sema.go:95 +0x25
internal/sync.(*Mutex).lockSlow(0xc0000100f0)
/home/going/go/go1.24.0/src/internal/sync/mutex.go:149 +0x15d
internal/sync.(*Mutex).Lock(...)
/home/going/go/go1.24.0/src/internal/sync/mutex.go:70
sync.(*Mutex).Lock(0xc0000100f8?)
/home/going/go/go1.24.0/src/sync/mutex.go:46 +0x2c
main.bar({0x4da100, 0xc0000100f0})
/home/going/golang/src/github.com/LiangNing7/conc/mutex/1.3mutex3/ReentrantLock.go:16 +0x22
main.foo({0x4da100, 0xc0000100f0})
/home/going/golang/src/github.com/LiangNing7/conc/mutex/1.3mutex3/ReentrantLock.go:11 +0x73
main.main()
/home/going/golang/src/github.com/LiangNing7/conc/mutex/1.3mutex3/ReentrantLock.go:23 +0x29
exit status 2实现可重入锁#
可重入锁的关键就是,实现的锁要能记住当前是哪个 goroutine 持有这个锁。有两个方案:
- 方案一:通过 hacker 的方式获取到 goroutine id,记录下获取锁的 goroutine id,它可以实现 Locker 接口。
- 方案二:调用 Lock/Unlock 方法时,由 goroutine 提供一个 token,用来标识它自己,而不是我们通过 hacker 的方式获取到 goroutine id,但是,这样一来,就不满足 Locker 接口了。
goroutine id#
该方案的关键是获取 goroutine id,方式有两种,简单方式和 hacker 方式。
简单方式是直接通过 runtime.Stack 方法获取栈帧信息,栈帧信息里包含 goroutine id。runtime.Stack 方法可以获取当前的 goroutine 信息,第二个参数为 true 会输出所有的 goroutine 信息,信息的格式如下:
goroutine 1 [running]:
main.main()
....../main.go:19 +0xb1第一行格式为 goroutine xxx,其中 xxx 就是 goroutine id,你只要解析出这个 id 即可。解析的方法可以采用下面的代码:
func GoID() int {
var buf [64]byte
n := runtime.Stack(buf[:], false)
// 得到id字符串
idField := strings.Fields(strings.TrimPrefix(string(buf[:n]), "goroutine "))[0]
id, err := strconv.Atoi(idField)
if err != nil {
panic(fmt.Sprintf("cannot get goroutine id: %v", err))
}
return id
}hacker 方式首先,我们获取运行时的 g 指针,反解出对应的 g 的结构。每个运行的 goroutine 结构的 g 指针保存在当前 goroutine 的一个叫做 TLS 对象中。
第一步:我们先获取到 TLS 对象;
第二步:再从 TLS 中获取 goroutine 结构的 g 指针;
第三步:再从 g 指针中取出 goroutine id。
注意,不同 Go 版本的 goroutine 的结构可能不同,需要根据 Go 的不同版本进行调整。也可以使用第三方包petermattis/goid。
$ go get github.com/petermattis/goid知道了如何获取 goroutine id,接下来就是最后的关键一步了,我们实现一个可以使用的可重入锁:
package mutex
import (
"fmt"
"sync"
"sync/atomic"
"github.com/petermattis/goid"
)
// RecursiveMutex 包装了一个 Mutex,实现可重入.
type RecursiveMutex struct {
sync.Mutex
owner int64 // 当前持有锁的 goroutine id.
recursion int32 // 这个 goroutine 重入次数.
}
func (m *RecursiveMutex) Lock() {
gid := goid.Get()
// 如果当前持有锁的 goroutine 就是这次调用的 goroutine,说明是重入.
if atomic.LoadInt64(&m.owner) == gid {
m.recursion++
return
}
m.Mutex.Lock()
// 获得锁的 goroutine 第一次调用,记录下它的 goroutine id,
// 调用次数加 1.
atomic.StoreInt64(&m.owner, gid)
m.recursion = 1
}
func (m *RecursiveMutex) Unlock() {
gid := goid.Get()
// 非持有锁的 goroutine 尝试释放锁,错误的使用.
if atomic.LoadInt64(&m.owner) != gid {
panic(fmt.Sprintf("wrong the owner(%d): %d!", m.owner, gid))
}
// 调用次数减 1.
m.recursion--
if m.recursion != 0 { // 如果这个 goroutine 还没完全释放,则直接返回.
return
}
// 此时 goroutine 的最后一次调用,需要释放锁.
atomic.StoreInt64(&m.owner, -1)
m.Mutex.Unlock()
}上面这段代码你可以拿来即用。我们一起来看下这个实现,真是非常巧妙,它相当于给 Mutex 打一个补丁,解决了记录锁的持有者的问题。可以看到,我们用 owner 字段,记录当前锁的拥有者 goroutine 的 id;recursion 是辅助字段,用于记录重入的次数。有一点,我要提醒你一句,尽管拥有者可以多次调用 Lock,但是也必须调用相同次数的 Unlock,这样才能把锁释放掉。这是一个合理的设计,可以保证 Lock 和 Unlock 一一对应。
token#
方案一是用 goroutine id 做 goroutine 的标识,我们也可以让 goroutine 自己来提供标识。不管怎么说,Go 开发者不期望你利用 goroutine id 做一些不确定的东西,所以,他们没有暴露获取 goroutine id 的方法。
下面的代码是第二种方案。调用者自己提供一个 token,获取锁的时候把这个 token 传入,释放锁的时候也需要把这个 token 传入。通过用户传入的 token 替换方案一中 goroutine id,其它逻辑和方案一一致。
package mutex
import (
"fmt"
"sync"
"sync/atomic"
)
// Token 方式的递归锁.
type TokenRecursiveMutex struct {
sync.Mutex
token int64
recursion int32
}
// 请求锁,需要传入 token.
func (m *TokenRecursiveMutex) Lock(token int64) {
// 如果传入的token和持有锁的token一致,说明是递归调用
if atomic.LoadInt64(&m.token) == token {
m.recursion++
return
}
m.Mutex.Lock() // 传入的 token 不一致
// 抢到锁之后记录这个 token.
atomic.StoreInt64(&m.token, token)
m.recursion = 1
}
// 释放锁.
func (m *TokenRecursiveMutex) Unlock(token int64) {
// 释放其他 token 持有的锁
if atomic.LoadInt64(&m.token) != token {
panic(fmt.Sprintf("wrong the owner(%d): %d!)", m.token, token))
}
// 当前持有这个锁的 token 释放锁.
m.recursion--
if m.recursion != 0 {
return
}
// 没有递归调用了,释放锁.
atomic.StoreInt64(&m.token, 0)
m.Mutex.Unlock()
}死锁#
两个或两个以上的进程(或线程,goroutine)在执行过程中,因争夺共享资源而处于一种互相等待的状态,如果没有外部干涉,它们都将无法推进下去,此时,我们称系统处于死锁状态或系统产生了死锁。
我们来分析一下死锁产生的必要条件。如果你想避免死锁,只要破坏这四个条件中的一个或者几个,就可以了。
- 互斥: 至少一个资源是被排他性独享的,其他线程必须处于等待状态,直到资源被释放。【这个条件不能被破坏,甚至还需要加以保护】
- 持有和等待:goroutine 持有一个资源,并且还在请求其它 goroutine 持有的资源,也就是咱们常说的“吃着碗里,看着锅里”的意思。
- 不可剥夺:资源只能由持有它的 goroutine 来释放。
- 环路等待:一般来说,存在一组等待进程,P={P1,P2,…,PN},P1 等待 P2 持有的资源,P2 等待 P3 持有的资源,依此类推,最后是 PN 等待 P1 持有的资源,这就形成了一个环路等待的死结。
Go 运行时,有死锁探测的功能,能够检查出是否出现了死锁的情况,如果出现了,这个时候你就需要调整策略来处理了。
Mutex 扩展#
TryLock#
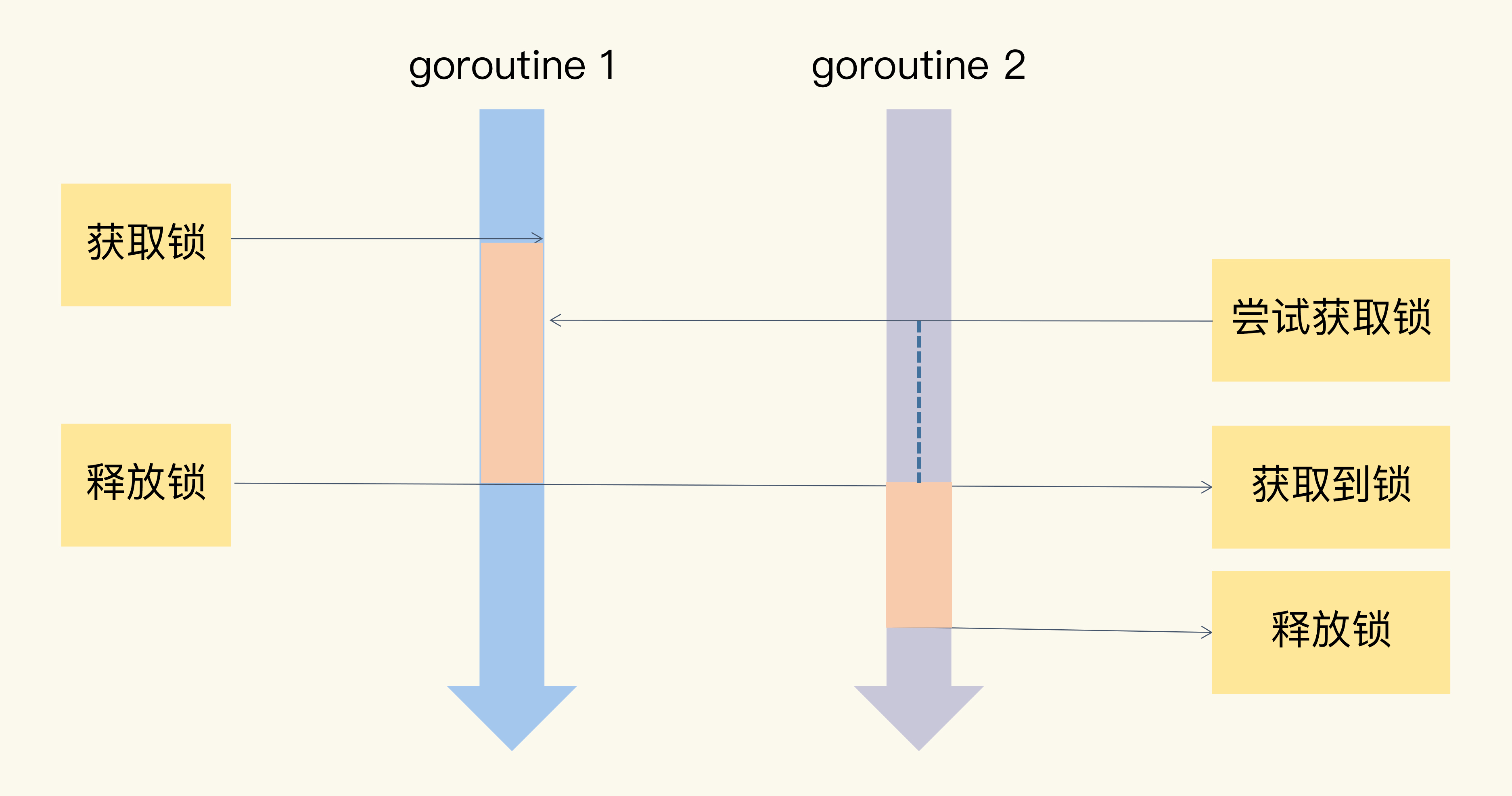
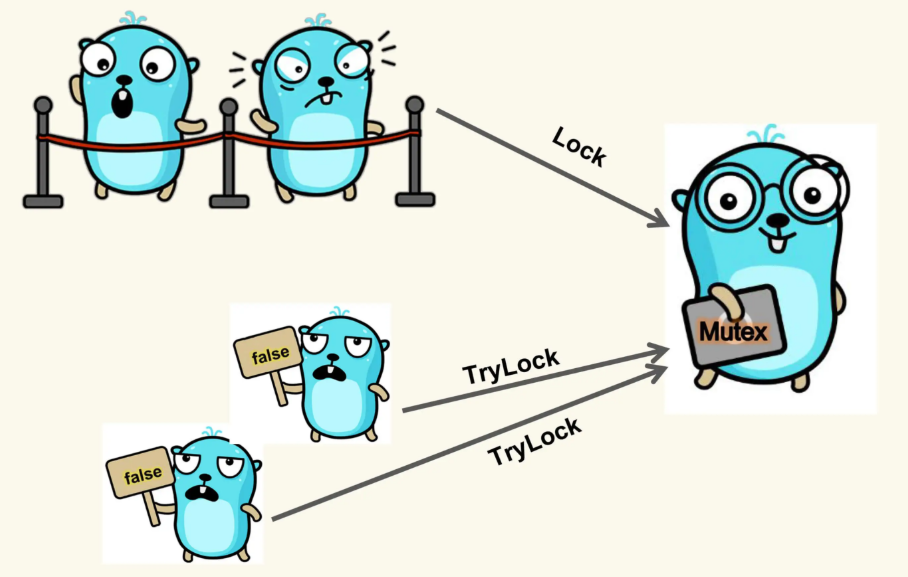
TryLock(),当一个 goroutine 调用这个 TryLock 方法请求锁的时候,如果这把锁没有被其他 goroutine 所持有,那么,这个 goroutine 就持有了这把锁,并返回 true;如果这把锁已经被其他 goroutine 所持有,或者是正在准备交给某个被唤醒的 goroutine,那么,这个请求锁的 goroutine 就直接返回 false,不会阻塞在方法调用上。
如下图所示,如果 Mutex 已经被一个 goroutine 持有,调用 Lock 的 goroutine 阻塞排队等待,调用 TryLock 的 goroutine 直接得到一个 false 返回。
在实际开发中,如果要更新配置数据,我们通常需要加锁,这样可以避免同时有多个 goroutine 并发修改数据。有的时候,我们也会使用 TryLock。这样一来,当某个 goroutine 想要更改配置数据时,如果发现已经有 goroutine 在更改了,其他的 goroutine 调用 TryLock,返回了 false,这个 goroutine 就会放弃更改。
基于 Mutex 扩展 TryLock#
代码如下:
package mutex
import (
"sync"
"sync/atomic"
"unsafe"
)
// 复制 Mutex 定义的常量.
const (
mutexLocked = 1 << iota // 1, 加锁标志位置
mutexWoken // 2, 唤醒标志位置.
mutexStarving // 4, 锁饥饿标识位置.
mutexWaiterShift = iota // 标识 waiter 的起始 bit 位置。
)
// 扩展一个 Mutex 结构.
type Mutex struct {
sync.Mutex
}
// TryLock() 尝试获取锁.
func (m *Mutex) TryLock() bool {
// 如果能成功抢到锁.
if atomic.CompareAndSwapInt32((*int32)(unsafe.Pointer(&m.Mutex)), 0, mutexLocked) {
return true
}
// 如果处于唤醒、加锁或者饥饿状态,这次请求就不参与了,返回 false.
old := atomic.LoadInt32((*int32)(unsafe.Pointer(&m.Mutex)))
if old&(mutexLocked|mutexStarving|mutexWoken) != 0 {
return false
}
// 尝试在竞争状态加锁.
new := old | mutexLocked
return atomic.CompareAndSwapInt32((*int32)(unsafe.Pointer(&m.Mutex)), old, new)
}第 25 行是一个 fast path,如果幸运,没有其他 goroutine 争这把锁,那么,这把锁就会被这个请求的 goroutine 获取,直接返回。
如果锁已经被其他 goroutine 所持有,或者被其他唤醒的 goroutine 准备持有,那么,就直接返回 false,不再请求,代码逻辑在第 30 行。
如果没有被持有,也没有其它唤醒的 goroutine 来竞争锁,锁也不处于饥饿状态,就尝试获取这把锁(第 37 行),不论是否成功都将结果返回。因为,这个时候,可能还有其他的 goroutine 也在竞争这把锁,所以,不能保证成功获取这把锁。
测试如下:
package mutex
import (
"fmt"
"math/rand"
"testing"
"time"
)
func TestTryLock(t *testing.T) {
var mu Mutex
go func() {
mu.Lock()
time.Sleep(time.Duration(rand.Intn(2)) * time.Second)
mu.Unlock()
}()
time.Sleep(time.Second)
ok := mu.TryLock()
if ok {
fmt.Println("got the lock")
// do something.
mu.Unlock()
return
}
// 没有获取到
fmt.Println("can't get the lock")
}程序运行时会启动一个 goroutine 持有这把我们自己实现的锁,经过随机的时间才释放。主 goroutine 会尝试获取这把锁。如果前一个 goroutine 一秒内释放了这把锁,那么,主 goroutine 就有可能获取到这把锁了,输出“got the lock”,否则没有获取到也不会被阻塞,会直接输出“can’t get the lock”。
获取等待者的数量指标#
Mutex 的数据结构,如下面的代码所示。它包含两个字段,state 和 sema。前四个字节(int32)就是 state 字段。
type Mutex struct {
state int32
sema uint32
}Mutex 结构中的 state 字段有很多个含义,通过 state 字段,你可以知道锁是否已经被某个 goroutine 持有、当前是否处于饥饿状态、是否有等待的 goroutine 被唤醒、等待者的数量等信息。但是,state 这个字段并没有暴露出来,所以,我们需要想办法获取到这个字段,并进行解析。
怎么获取未暴露的字段呢?很简单,我们可以通过 unsafe 的方式实现。
示例如下:
package mutex
import (
"sync/atomic"
"unsafe"
)
// Count 持有和等待这把锁的 goroutine 的总数
func (m *Mutex) Count() int {
// 获取 state 字段的值.
v := atomic.LoadInt32((*int32)(unsafe.Pointer(&m.Mutex)))
v = v>>mutexWaiterShift + (v & mutexLocked)
return int(v)
}
// IsLocked 锁是否被持有.
func (m *Mutex) IsLocked() bool {
state := atomic.LoadInt32((*int32)(unsafe.Pointer(&m.Mutex)))
return state&mutexLocked == mutexLocked
}
// IsWoken 是否有等待者被唤醒.
func (m *Mutex) IsWoken() bool {
state := atomic.LoadInt32((*int32)(unsafe.Pointer(&m.Mutex)))
return state&mutexLocked == mutexWoken
}
// IsStarving 锁是否饥饿.
func (m *Mutex) IsStarving() bool {
state := atomic.LoadInt32((*int32)(unsafe.Pointer(&m.Mutex)))
return state&mutexStarving == mutexStarving
}Count()函数通过 atomic.LoadInt32((*int32)(unsafe.Pointer(&m.Mutex)))得到 state 字段的值,由于该字段末尾的 3 个 bit 表示其他含义,右移之后,就得到了当前等待者的数量.然后加上 当前持有者的数量就得到了当前持有和等待这把锁的 goroutine 的总数。
其他函数也是通过如上处理得到。
使用 Mutex 实现一个线程安全的队列#
比如队列,我们可以通过 Slice 来实现,但是通过 Slice 实现的队列不是线程安全的,出队(Dequeue)和入队(Enqueue)会有 data race 的问题。这个时候,Mutex 就要隆重出场了,通过它,我们可以在出队和入队的时候加上锁的保护。
package mutex
import (
"sync"
)
type SliceQueue struct {
data []any
mu sync.Mutex
}
func NewSlcieQueue(n int) (q *SliceQueue) {
return &SliceQueue{data: make([]any, 0, n)}
}
// Enqueue 把值放在队尾.
func (q *SliceQueue) Enqueue(v any) {
q.mu.Lock()
defer q.mu.Unlock()
q.data = append(q.data, v)
}
// Dequeue 去掉对头并返回.
func (q *SliceQueue) Dequeue() any {
q.mu.Lock()
defer q.mu.Unlock()
if len(q.data) == 0 {
q.mu.Unlock()
return nil
}
v := q.data[0]
q.data = q.data[1:]
return v
}因为标准库中没有线程安全的队列数据结构的实现,所以,你可以通过 Mutex 实现一个简单的队列。通过 Mutex 我们就可以为一个非线程安全的 data any 实现线程安全的访问。
总结#