Count 主键和 Count 非主键 性能相同吗?结果会不同吗?#
count() 是一个聚合函数,函数的参数不仅可以是字段名,也可以是其他任意表达式,该函数作用是统计符合查询条件的记录中,函数指定的参数不为 NULL 的记录有多少个。
- 字段名:
select count(name) from t_order;这条语句是统计「t_order表中,name 字段不为 NULL 的记录」有多少个。也就是说,如果某一条记录中的 name 字段的值为 NULL,则就不会被统计进去。 - 表达式:
select count(1) from t_order;这条语句是统计「t_order 表中,1 这个表达式不为 NULL 的记录」有多少个。1 这个表达式就是单纯数字,它永远都不是 NULL,所以上面这条语句,其实是在统计 t_order 表中有多少个记录。
count(主键字段)的执行过程如下:
在通过 count 函数统计有多少个记录时,MySQL 的 server 层会维护一个名叫 count 的变量。
server 层会循环向 InnoDB 读取一条记录,如果 count 函数指定的参数不为 NULL,那么就会将变量 count 加 1,直到符合查询的全部记录被读完,就退出循环。最后将 count 变量的值发送给客户端。
InnoDB 是通过 B+ 树来保存记录的,根据索引的类型又分为主键索引【聚簇索引】和非主键索引【二级索引】,它们区别在于,主键索引的叶子节点存放的是实际完整的数据,而二级索引的叶子节点存放的是非主键值+主键ID,而不是实际完整数据。
┌────────────────────────────────────────────────────────┐ │ 【非主键索引】 (二级索引) │ │ (例如:以 name 字段建树) │ └────────────────────────────────────────────────────────┘ │ [ 非叶子节点: 'Bob' ] / \ / \ ┌────────────────────┐ ┌──────────────────────┐ │ 叶子节点: │ │ 叶子节点: │ │ name='Alice' │ │ name='Charlie' │ │ 主键 id=10 │ │ 主键 id=30 │ │ (只存索引值+主键) │ │ (只存索引值+主键) │ └────────────────────┘ └──────────────────────┘ │ │ 发现没有 age 字段,拿着 id=10 去下面那棵树找 │ (这个动作就是传说中的【回表】) ▼ ┌────────────────────────────────────────────────────────┐ │ 【主键索引】 (聚簇索引) │ │ (必定以主键 id 建树) │ └────────────────────────────────────────────────────────┘ │ [ 非叶子节点: id=20 ] / \ / \ ┌────────────────────┐ ┌──────────────────────┐ │ 叶子节点: │ │ 叶子节点: │ │ id=10 │ │ id=30 │ │ name='Alice' │ │ name='Charlie' │ │ age=25 │ │ age=35 │ │ (这是一整行完整数据)│ │ (这是一整行完整数据) │ └────────────────────┘ └──────────────────────┘
用下面这条语句作为例子:
//id 为主键值
select count(id) from t_order;如果表里只有主键索引,没有二级索引时,那么,InnoDB 循环遍历主键索引,将读取到的完整的记录返回给 server 层,然后读取记录中的 id 值,就会用 id 值判断是否为 NULL,如果不为 NULL,就将 count 变量加 1。
但是,如果表里有二级索引时,InnoDB 循环遍历的对象就不是主键索引,而是非主键索引。
这是因为相同数量的非主键索引记录可以比主键索引记录占用更少的存储空间,所以非主键索引树比主键索引树小,这样遍历非主键索引的 I/O 成本比遍历主键索引的 I/O 成本小,因此「优化器」优先选择的是非主键索引。
count(非主键字段)的执行过程如下:
用下面这条语句作为例子:
select count(name) from t_order;对于这个查询来说,如果没有基于 name 建立索引,那么为了获取到 name 的值,只能走主键索引,获取完整的数据,然后采用全表扫描的方式来计数,所以它的执行效率是比较差的。
如果基于 name 建立了索引,那么还是可以走该非主键索引的,因为该索引树上刚好存储了 name 的值,不需要进行全表扫描。
回答#
如果 非主键字段没有建立索引【而该表中建立了其他二级索引】,那么 Count(主键) 走二级索引,而 Count(非主键) 是走主键索引进行全表扫描
主键是不能存NULL值的,所以 count 主键代表统计表中所有行数据的数量。
而非主键是可以存NULL值的,所以 count 非主键统计的是表中这个列的非NULL值的数量。
Count(1) 和 Count(*) 有何区别,那个性能最好?#
count(1) 执行过程如下:
用下面这条语句作为例子:
select count(1) from t_order;如果表里只有主键索引,没有二级索引时。
那么,InnoDB 循环遍历主键索引,将读取到的记录返回给 server 层,但是不会读取记录中的任何字段的值,因为 count 函数的参数是 1,不是字段,所以不需要读取记录中的字段值。参数 1 很明显并不是 NULL,因此 server 层每从 InnoDB 读取到一条记录,就将 count 变量加 1。
可以看到,count(1) 相比 count(主键字段) 少一个步骤,就是不需要读取记录中的字段值,所以通常会说 count(1) 执行效率会比 count(主键字段) 高一点。
不过需要注意,上面这个结论只适用于「表里没有任何二级索引、只能扫主键索引」这种场景。如果表上存在二级索引,优化器会把 count(主键字段) 也改写成扫描 key_len 最小的二级索引,此时 count(1) 和 count(主键字段) 的执行过程完全一致,性能上没有差异。
但是,如果表里有二级索引时,InnoDB 循环遍历的对象就是二级索引了。
count(*) 执行过程如下:
count(*) 其实等于 count(0),也就是说,当你使用 count(*) 时,MySQL 会将 * 参数转化为参数 0 来处理。
所以,count(*) 执行过程跟 count(1) 执行过程基本一样的,性能没有什么差异。而且 MySQL 会对 count(*) 和 count(1) 有个优化,如果有多个二级索引的时候,优化器会使用 key_len 最小的二级索引进行扫描。只有当没有二级索引的时候,才会采用主键索引来进行统计。
回答#
MySQL 会将星号参数转化为参数 0 来处理,所以count(*) 和count(1) 性能是一样的。
MySQL 的内连接、外连接有什么区别?#
内连接(INNER JOIN):内连接返回两个表中匹配的行,即只返回两个表中共有的数据。
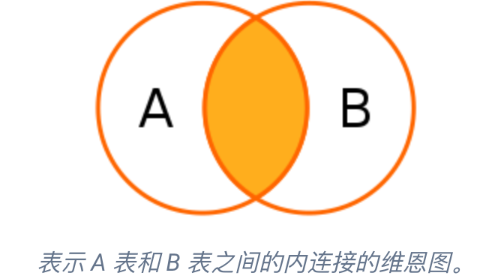
外连接(OUTER JOIN):外连接则返回两个表中匹配和不匹配的行。MySQL 外连接主要有左外连接(LEFT JOIN)、右外连接(RIGHT JOIN)两种。
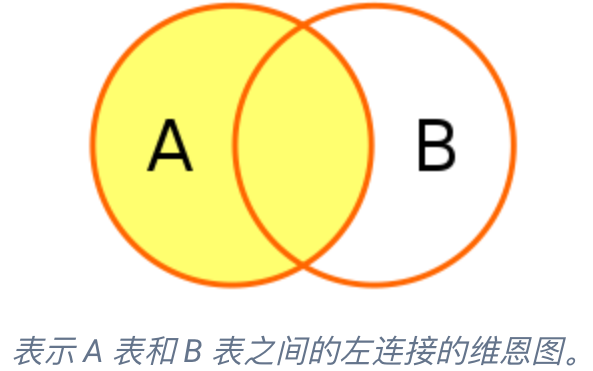
左连接(LEFT JOIN):SELECT * FROM A LEFT JOIN B ON A.A_id = B.B_id,将返回左表 A 中的所有行和右表 B 中与之匹配的行。如果 B 表中没有匹配的行,则 B 表相关的列使用 NULL 值填充。
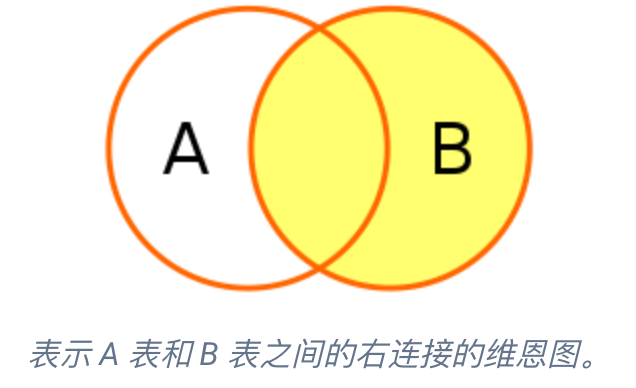
右连接(RIGHT JOIN):SELECT * FROM A RIGHT JOIN B ON A.A_id = B.B_id,将返回右表 B 中的所有行和左表 A 中与之匹配的行。如果 A 表中没有匹配的行,则 A 表相关的列使用 NULL 值填充
回答#
内连接和外连接都是用于连表查询。
内连接是只返回两个表匹配的数据行,外连接可以返回两个表匹配和不匹配的数据行,外连接主要分为左连接和右连接。
- 左连接返回左表中的所有行和右表中匹配的行,如果右表中没有匹配的行,则用 NULL 值填充。
- 右连接返回右表中的所有行和左表中匹配的行,如果左表中没有匹配的行,则用 NULL 值填充
外连接时 on 和 where 过滤条件区别?#
回答#
- 对于内连接(inner join)查询,WHERE和ON中的过滤条件等效;
- 对于外连接(outer join)查询,ON中的过滤条件在连接时进行,WHERE中的过滤条件在连接操作之后执行。
having与where的区别?#
WHERE 与 HAVING 的根本区别在于:
- WHERE 子句在 GROUP BY 分组和聚合函数之前对数据行进行过滤,where 子句无法使用聚合函数。
- HAVING 子句对 GROUP BY 分组和聚合函数之后的数据行进行过滤,having 子句可以使用聚合函数。
回答#
在 GROUP BY 分组查询过程中,Where 是工作在GROUP BY之前,Where 是对分组之前的数据进行筛选,无法使用聚合函数,Having 是工作在GROUP BY之后,Having 主要对分组之后的数据进行筛选,可以使用聚合函数。
EXISTS 和 IN的区别是什么?#
in 和 exists 一般用于子查询,语法如下:
select * from A where id in (select id from B);
select * from A where exists (select 1 from B where A.id=B.id);in 的工作原理:
IN() 里的查询只会执行一次,它先查出 B 表中的所有 id 字段并缓存起来。之后,检查 A 表的 id 是否与 B 表中的 id 相等(在内存判断),如果相等则将 A 表的记录加入结果集中,直到遍历完 A 表的所有记录。它的查询过程类似于以下过程:
List resultSet={};
Array A=(select * from A);
Array B=(select id from B);
for(int i=0;i<A.length;i++) {
for(int j=0;j<B.length;j++) {
if(A[i].id==B[j].id) {
resultSet.add(A[i]);
break;
}
}
}
return resultSet;如果 B 表的结果集没有建立有效索引,外表 A 遍历 $N$ 次,每次在 B 的结果集中查找,最坏情况复杂度为 $O(N \times M)$。
实际上,MySQL 通常会将 IN 的结果集构建为哈希表(Hash Table),或者利用 B 表的索引。如果内表 B 被物化为哈希表,复杂度可以近似为 $O(M + N)$。
exist 的工作原理:
exists() 会执行 A.length 次,它并不缓存 exists() 结果集,因为 exists() 结果集的内容并不重要,重要的是其内查询语句(执行内查询 sql,会查数据库)的结果集空或者非空,空则返回 false,非空则返回 true。它的查询过程类似于以下过程:
List resultSet={};
Array A=(select * from A);
for(int i=0;i<A.length;i++) {
if(exists(A[i].id) { //执行select 1 from B where B.id=A.id是否有记录返回
resultSet.add(A[i]);
}
}
return resultSet;如果内表 B 的关联字段(B.id)没有索引,每次验证都要全表扫描 B,复杂度为 $O(N \times M)$。
如果内表 B 的关联字段有索引(通常是 B 树索引),每次验证的查找复杂度降为 $O(\log M)$。总时间复杂度为 $O(N \log M)$。
回答#
| 特性 | IN | EXISTS |
|---|---|---|
| 驱动顺序 | 内表 B 驱动外表 A | 外表 A 驱动内表 B |
| 执行次数 | 内查询执行 1 次,外表遍历 $N$ 次 | 外表遍历 $N$ 次,内查询执行 $N$ 次 |
| 最优时间复杂度 | $\approx O(M + N)$ (依赖哈希或物化) | $\approx O(N \log M)$ (依赖 B 表索引) |
| 最佳适用场景 | B 表小,A 表大 | A 表小,B 表大(且 B 有索引) |
mysql 的约束有哪些?#
回答:
数据库的约束主要有 6 大约束,分别是主键约束、外键约束、唯一性约束、非空约束、默认约束、检查约束,MySQL只支持前 5 钟约束,不支持检查约束。
MySQL 支持的这些约束的作用如下:
- 主键约束的作用唯一标识一条记录,不能重复也不能为空,一张表数据库表只能有一个主键,一般我们会针对 id 字段设置为主键
- 外键约束的作用是确保表与表之间引用的完整性
- 唯一性约束的作用是保证字段在表中的数值是唯一的,如果插入相同字段值的记录,就会报唯一性约束的错误。
- 非空约束的作用是保证字段不能为 NULL
- 默认约束的作用是给字段设置默认值,如果插入数据的时候,这个字段没有取值的话,就会用默认值
delete、drop、truncate有什么区别?#
| 区别点 | drop | truncate | delete |
|---|---|---|---|
| 执行速度 | 快 | 较快 | 慢 |
| 命令分类 | DDL(数据定义语言) | DDL(数据定义语言) | DML(数据操作语言) |
| 删除对象 | 删除整张表和表结构,以及表的索引、约束和触发器。 | 只删除表数据,表的结构、索引、约束等会被保留。 | 只删除表的全部或部分数据,表结构、索引、约束等会被保留。 |
| 删除条件(where) | 不能用 | 不能用 | 可使用 |
| 回滚 | 不可回滚 | 不可回滚 | 可回滚 |
| 自增初始值 | - | 重置 | 不重置 |
联合查询中 union 和 union all的区别是什么?#
与 Join 的区别?
Join 是添加列,而 union 是增加行。
- UNION:在合并结果集后会自动剔除重复的行。
- UNION ALL:则会保留所有的重复行,不会进行去重操作。
