查询 SQL 语句的全过程#
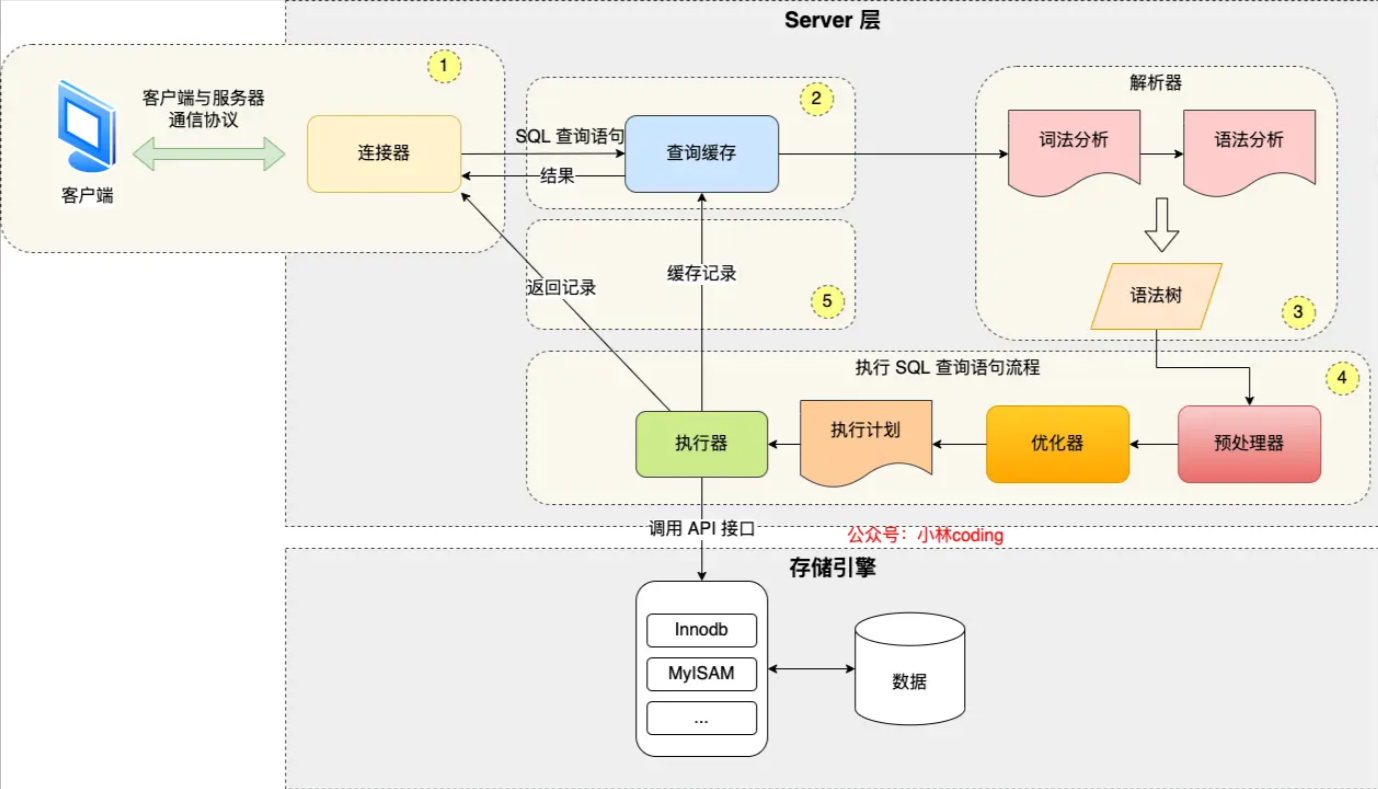
考察对 MySQL 整体架构的理解和认识,大体的流程如下图:
回答#
MySQL 执行一条查询 SQL 语句的时候,会经过连接器、查询缓存、解析器、优化器、执行器、存储引擎这些模块。
- 首先 MySQL 的连接器会负责建立连接、校验用户身份、接收客户端的 SQL 语句;
- 第二步 MySQL 会在查询缓存中查找数据,如果命中直接返回数据给客户端,否则就需要继续往下查询,不过查询缓存功能在MySQL 8.0 版本被删除了,原因是只要对这张表进行了写操作,这张表的查询缓存就会失效,所以在实际场景中,查询缓存的命中率其实不高;
- 第三步 MySQL 的解析器会对 SQL 语句进行词法分析和语法分析,然后构建语法树,方便后续模块读取表名、字段、语句类型;
- 第四步 MySQL 的优化器会基于查询成本的考虑,会判断每个索引的执行成本,从中选择查询成本最小的执行计划;
- 第五步 MySQL 的执行器会根据执行计划来执行查询语句,从存储引擎读取记录,返回给客户端;
char 和 varchar 有什么区别?追问:哪个性能更好?#
- char 是固定长度的字符串类型,它在数据库中占用固定的存储空间,无论实际存储的数据长度是多少,都会占用定义时指定的固定长度,如果实际存储的字符串长度小于定义的长度,系统会自动用空格填充。比如如果定义一个char(10)类型的字段,即使实际数据只使用 5 字节,会自动填充 5 字节的空格,使得存储空间固定占用 10 字节。
- Varchar 是可变长度的字符串类型。实际存储时只占用实际字符串长度的空间,不会进行空格填充。比如如果定义一个varchar(10)类型的字段,并存储了一个长度为5的字符串,那么它只会占用5个字节的存储空间,并且还会额外用 1-2 字节存储「可变长字符串长度」的空间。
如果硬件内存特别大,MySQL 缓存能否替代 redis?#
回答#
不能完全替代。 内存再大,MySQL 也无法突破自身基于磁盘和事务设计的架构局限。
- 计算路径: MySQL 即使全命中缓存,也要经过沉重的 SQL 解析、优化器生成执行计划 等流程;Redis 协议轻量,纯内存几乎直接寻址。
- 并发锁机制: MySQL 为保证 ACID 必须维护复杂的行锁、间隙锁和 MVCC,高并发下 CPU 上下文切换严重;Redis 采用单线程+多路复用,天生无锁化,规避了锁竞争瓶颈。
- 特定业务场景: Redis 提供的毫秒级排行榜(ZSet)、高并发秒杀原子扣减(INCR)、过期机制等功能,大内存的 MySQL 依然难以低成本实现。
