Mysql 有哪些索引类型?#
索引都是由存储引擎来实现的,不同存储引擎支持的索引类型也是不同的。大多数存储引擎都是支持 B+ 树索引,而哈希索引只有 Memory 引擎实现了。
B+ 树索引、哈希索引、全文索引的区别:
- B+ 树索引:B+ 树索引是一种平衡树数据结构,它将数据按照索引键值有序地存储在树的叶子节点上,非叶子节点只存储索引键值和指向下一层节点的指针,适合于范围查找、排序查询、等值查询的情况,并且性能稳定,因为 B+ 树保存千万级别的数据,树的高度依然维持在 3
4 层左右,也就是从千万级数据查询一条数据只需要 34 次的磁盘 I/O 操作就能查询到目标数据。 - 哈希索引:哈希索引是通过哈希算法将键值(key-value)映射到哈希表中,再根据哈希表进行索引操作。哈希索引适合于等值查询,例如根据主键查询某条记录,查询时间复杂度为O(1),效率非常高,但不支持排序、范围查询及模糊查询等。
- 全文索引:全文索引是一种用于全文搜索的索引技术,可以对文本内容进行索引,支持关键词的模糊匹配和搜索。一般用于查找文本中的关键字,而不是直接比较是否相等,主要是用来解决
WHERE name LIKE “%aaaa%”等针对文本的模糊查询效率低的问题。
回答#
MySQL 支持 B+ 树索引、哈希索引、全文索引这三种索引类型。 我比较常用的是 B+ 树索引,因为它是 InnodB 引擎默认使用的索引类型,支持排序、分组、范围查询、模糊查询等功能。
InnodB 引擎的索引数据结构是什么?#
回答#
我了解到 InnodB 引擎是采用了 B+ 树作为索引的数据结构。它的一些特性:
- 数据组织形式:InnodB 存储引擎的主键索引 B+ 树的非叶子节点只存放索引键值和指向子节点的指针,不存储实际的数据,这里对应到MySQL中就是索引,叶子节点存储索引键值和行数据,所以 InnodB 存储引擎的主键索引属于聚簇索引
- 叶子节点链表:所有叶子节点通过指针相连,形成一个双向链表,支持快速的顺序访问和范围查询。
- 平衡树结构:所有叶子节点在同一层上,树的高度平衡,保证任何数据记录的查找、插入、删除和更新操作的路径长度相同,稳定性好。
B+ 树的特点是什么?#
至少回答出 B+树这 2 个特点:
- 叶子节点会存储索引+数据,中间节点不会存储数据
- 叶子节点之间用双向链表组织
回答#
B+树是一个多叉树,一个父节点,可以有多个子节点,主要的特性有三个:
- B+树的中间节点不会存储数据,而只有叶子节点才会存储,中间节点只用于存储到叶子节点的路由信息(即索引),而且每个节点里的数据都是根据索引的值来顺序存放的
- B+树的所有的叶子节点之间会通过双向指针串联在一起,构成一个双向链表,可以方便扫表和范围查询
- B+ 查询性能稳定,因为所有叶子节点都在同一层**,**确保了所有数据项的检索都具有相同的 I/O 延迟,而且 B+ 树保存千万级别的数据,树的高度依然维持在 3
4 层左右,也就是从千万级数据查询一条数据只需要 34 次的磁盘 I/O 操作就能查询到目标数据。
B 树和 B+ 树的区别#
从三个角度来说明区别:
- 数据存储的区别;
- 范围查询的区别;
- 查询效率的区别。
回答#
B+ 和 B 树都是多叉平衡树,每个节点包含多个键和多条链,主要的区别有这些:
- B 树所有节点都会存储索引+数据,而 B+ 树只有叶子节点才会存储数据,中间节点则只有索引,因此存储相同数据量的情况下, B+ 树可以比 B 树更矮胖,查询叶子节点的磁盘 I/O次数会更少;
- B+树叶子节点之间会通过双向指针串联在一起,构成一个双向链表,这种设计对范围查找非常有帮助,而 B 树没有将所有叶子节点用链表串联起来的结构,只能通过中序遍历来完成范围查询,这会比B+树范围查询涉及更多个节点的磁盘 I/O 操作,因此范围查询效率不如 B+ 树;
- B 树的优势是当你要查找的值恰好处在一个非叶子节点时,由于该节点也包含数据,查找到该节点就会成功并结束查询,最快可以在 O(1) 的时间代价内就查到,而 B+ 树由于数据只在叶子节点,所以每次查询都需要从根节点搜索到叶子节点,从平均时间代价来看,会比 B+ 树稍快一些,但是B+树的查询会更稳定,因为每次查询都是相同的I/O延迟
MySQL 为什么使用 B+ 树#
这种面试官没有问 B+ 树和其他数据结构区别的问题,就需要自己主动去对比,比如平衡树、红黑树、跳表、B树。
对比:
- 二叉树:B+树的层数更低,利于磁盘 IO,B+ 树还可以范围查询;
- Hash:B+树利于范围查询;
- 跳表:跳表在极端情况会退化为链表,平衡性差
- B 树:B树不利于范围查询,B+ 树可以范围查询
回答#
- B+ 树是多叉树,而平衡二叉树、红黑树是二叉树,在同等数据量下,平衡二叉树、红黑树高度更高,磁盘 IO 次数更多,性能更差,而且它们会频繁执行再平衡过程,来保证树形结构平衡。
- 跳表和 B+ 树相比,跳表在极端情况下会退化为链表,平衡性差,而数据库查询需要一个可预期的查询时间,并且跳表需要更多的内存。
- B 树和B+树相比,B 树的数据存储在全部节点中,对范围查询不友好。非叶子节点存储了数据,导致内存中难以放下全部非叶子节点。如果内存放不下非叶子节点,那么就意味着查询非叶子节点的时候都需要磁盘 IO。
聚簇索引和非聚簇索引#
回答#
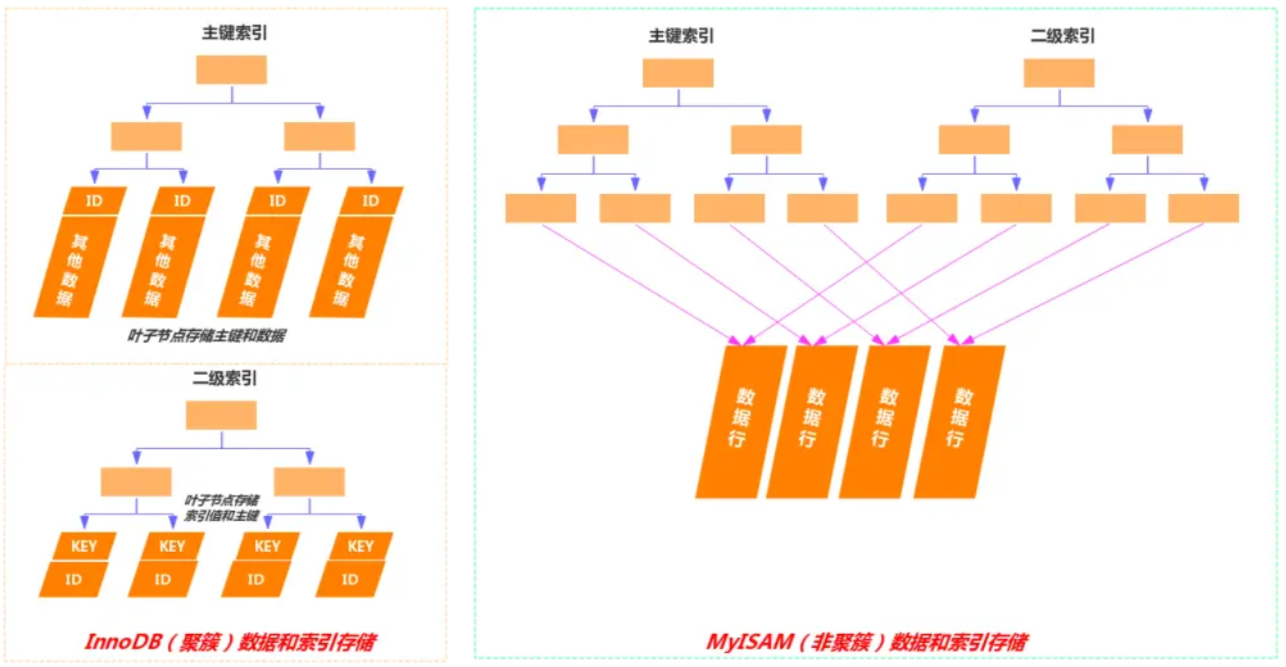
聚簇索引和非聚簇索(二级索引)引最主要的区别是 B+ 树叶子节点存放的内容不同:
- 聚簇索引的 B+树叶子节点存放的是主键值+完整的记录;
- 非聚簇索引的 B+树叶子节点存放的是索引值+主键值;
如果查询语句的查询条件用了二级索引,但是查询的数据不是主键值,也不是二级索引值,这时在二级索引找到主键值后,就需要回表才能查找到数据,,需要扫描两次B+树。如果查询的列是主键值和二级索引值时,因为只在二级索引就能查询到,这时候就会用到覆盖索引,不需要回表,只需要扫描一次B+树。
什么是覆盖索引#
二级索引的叶子节点存放的是索引+主键 id,如果查询的列能够在二级索引中全部查询到,那就不需要回到主键索引去查行记录了,这种不需要回表的过程,就叫覆盖索引,效率会比较高。
假设有联合索引(a,b),当执行以下查询的时候,都会发生覆盖索引:
select a, b, id from table where a= ? and b =?;
select a, b from table where a= ? and b =?;
select a, id from table where a= ? and b =?;
select b, id from table where a= ? and b =?;
select a from table where a= ? and b =?;
select b from table where a= ? and b =?;
select id from table where a= ? and b =?;回答#
当查询的数据是能在二级索引的叶子节点里查询到的话,这时就不用再回主键索引查了,那就不需要回到主键索引去查行记录了,这种不需要回表的过程,就叫覆盖索引,这种查询方式效率会比较高,只需要查二级索引这一棵 B+ 树。
什么情况需要回表#
在使用二级索引进行查询的时候,如果查询的列,不能在二级索引中全部查询到,那么就需要回到主键索引去查完成的行记录了,这种二级索引通过主键索引进行再一次查询的操作叫作「回表」。
我这里将商品表中的 product_no (商品编码)设置为二级索引,那么这个二级索引的**索引键值是product_no,B+ 树会根据product_no索引键值的顺序来存储数据,**那么二级索引的 B+ 树如下图:
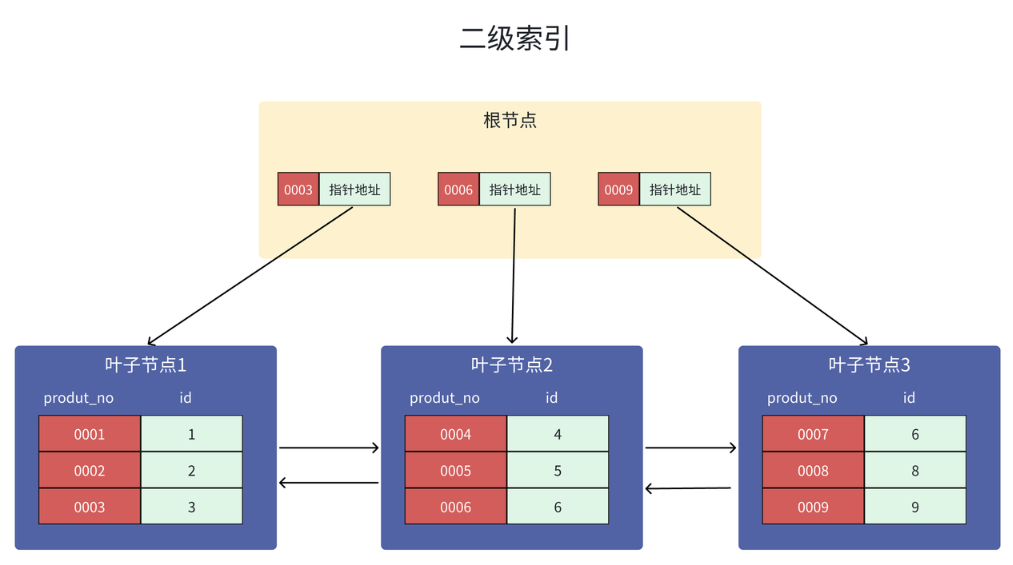
上图中,非叶子节点的索引键值是 product_no(图中红色部分),叶子节点存储是索引键值(图中红色部分)+主键值(图中绿色部分)。
如果我用 product_no 二级索引查询商品,如下查询语句:
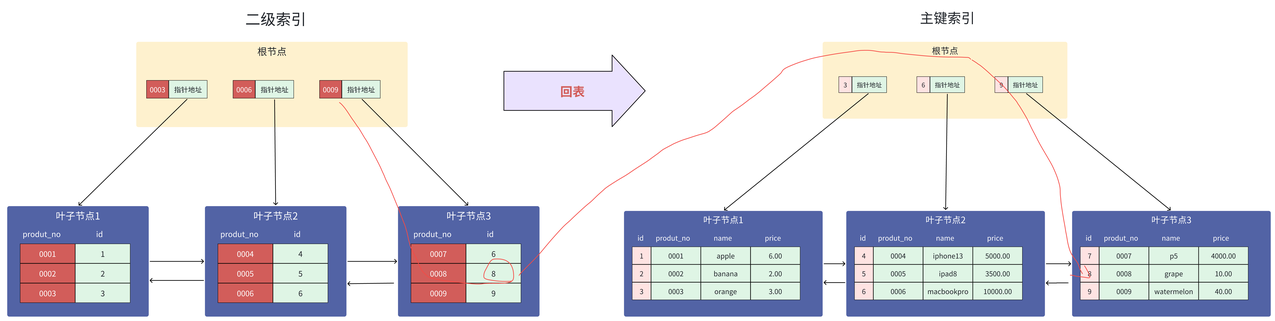
select * from product where product_no = '0008';查询过程是这样的,先从二级索引 B+ 树自顶向下逐层进行查找:
- 将 0008 与根节点的索引 (0003,0006,0009) 比较,0008 大于索引值 0006,说明 0008 肯定不在叶子节点 2,因为索引值 6 是叶子节点 2 中最大的索引值,0008 小于索引值 0009,这表示小于 0009 的数据在地址指向的下一层节点中,根节点索引键 0009 的指针地址指向的是「叶子节点 3」,因此这里定位的是 0008 在「叶子节点 3」 中
- 在「叶子节点 3 」中根据二分查找算法就能找到索引键值为 0008 的数据,但是这时候只能查到主键值(id = 8),而无法查询到完整的行记录,因为二级索引并不会存储完整的行记录,所以需要额外再通过主键索引到主键索引中查询到对应的叶子节点,这时候才能获取完整的行记录,也就是说要查两个 B+ 树才能查到最终的结果
这种二级索引通过主键索引进行再一次查询的操作叫作「回表」,你可以通过下图理解二级索引的查询过程:
回答#
在使用二级索引进行查询的时候,如果查询的列,不能在二级索引中全部查询到,那么就会发生回表的过程,先通过二级索引的值查到聚簇索引值(即主键 id),再通过聚簇索引的值定位行记录数据,需要扫描两次索引 B+ 树,它的性能较扫一遍索引树更低。
