持久化介绍#
Redis 是跑在内存里的,当程序重启或者服务崩溃,数据就会丢失,如果业务场景希望重启之后数据还在,就需要持久化,即把数据保存到可永久保存的存储设备中。
Redis提供两种方式来持久化:
RDB(Redis Database Backup),记录 Redis 某个时刻的全部数据,这种方式本质就是数据快照,直接保存二进制数据到磁盘,后续通过加载RDB文件恢复数据。
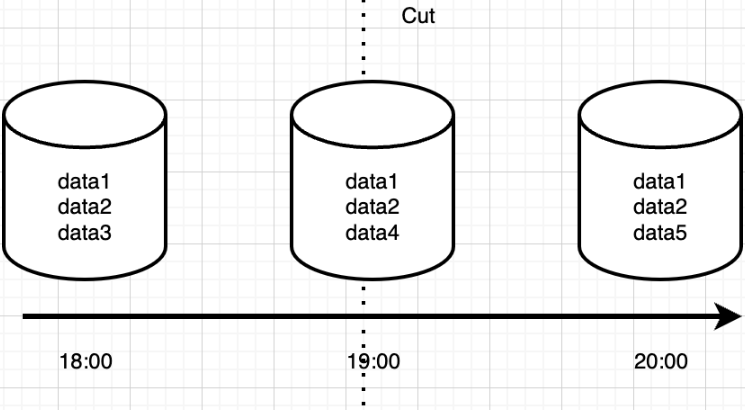
AOF(Append Only File),记录执行的每条命令,重启之后通过重放命令来恢复数据,AOF本质是记录操作日志,后续通过日志重放恢复数据。

RDB是快照恢复,AOF是日志恢复,这是两者本质区别,我们甚至都不用去学习他们具体的实现,也能推测出他们如有下差别:
- 体积方面:相同数据量下,RDB体积更小,因为RDB是记录的二进制紧凑型数据;
- 恢复速度:RDB是数据快照,可以直接加载,而AOF文件恢复,相当于重放情况,RDB显然会更快;
- 数据完整性:AOF记录了每条日志,RDB是间隔一段时间记录一次,用AOF恢复数据通常会更为完整。
RDB 详解#
怎么开启RDB持久化#
我们先从实践上入手,看一下怎么开启RDB持久化。
首先,我们打开 redis 配置文件:/usr/local/etc/redis.conf
在其中搜索可以发现如下配置:
save 900 1
save 300 10
save 60 10000这里的配置语法是 save interval num,表示每间隔 interval 秒,至少有 num 条写数据操作,写数据操作指增加、删除及更新,就会激活 RDB 持久化。
他们之间是并集关系,即只要满足其中一个条件,就达到了RDB持久化的条件,有同学也问到,这里触发的save命令,还是bgsave命令?这里显然是bgsave,不然如果用save,时不时阻塞一下怎么行。
这三条配置不是我们增加,是默认就存在的,这就是说redis默认已经开启了RDB持久化。
RDB 文件存哪里?#
下面的参数决定了文件会存到哪里
# The filename where to dump the DB
dbfilename dump.rdb
# The working directory.
dir /Users/niuniumart/code/redis什么时候进行持久化#
Redis持久化会在下面四种情况下进行:
主动执行命令save
127.0.0.1:6379> save OKRedis服务会有对应输出
71359:M 12 Feb 2026 08:29:26.507 * DB saved on disk执行了 save 命令,就会在主线程生成 RDB 文件,由于和执行操作命令在同一个线程,所以如果写入 RDB 文件的时间太长,会阻塞主线程,这个命令慎用。
主动执行命令bgsave
127.0.0.1:6379> bgsave Background saving startedRedis服务会有对应输出:
71359:M 12 Feb 2026 08:29:33.412 * Background saving started by pid 71902 71902:C 12 Feb 2026 08:29:33.414 * DB saved on disk 71359:M 12 Feb 2026 08:29:33.456 * Background saving terminated with success和save不同,会创建一个子进程来生成 RDB 文件,这样可以避免主线程的阻塞。
达到持久化配置阈值
上面有提到,Redis可以配置持久化策略,达到策略就会触发持久化,这里的持久化使用的方式是后台save,从这可以看到Redis比较推荐的方式也是后台执行持久化,尽可能减少对主流程影响。达到阈值之后,是由周期函数触发持久化。
还会在程序正常关闭的时候执行
在关闭时,Redis 会启动一次阻塞式持久化,以记录更全的数据
54354:M 01 Jan 2026 09:17:26.527 # User requested shutdown... 54354:M 01 Jan 2026 09:17:26.528 * Saving the final RDB snapshot before exiting. 54354:M 01 Jan 2026 09:17:26.529 * DB saved on disk所以正常关闭丢失的数据不会丢失,崩溃才会。
RDB 具体做了什么#
我们这里聚焦达到 RDB 持久化策略时,是如何进行持久化的,我们先看一下Redis 输出:
62581:M 01 Jan 2026 09:04:26.279 * 1 changes in 3600 seconds. Saving...
62581:M 01 Jan 2026 09:04:26.281 * Background saving started by pid 50162
50162:C 01 Jan 2026 09:04:26.283 * DB saved on disk
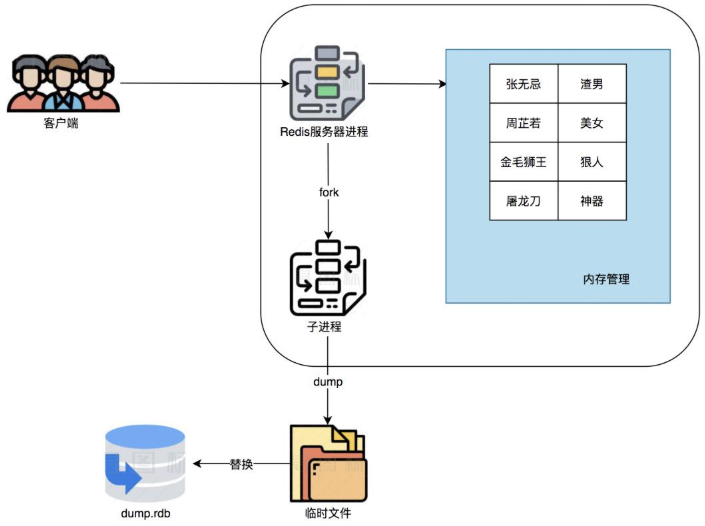
62581:M 01 Jan 2026 09:04:26.383 * Background saving terminated with success从输出能看出,RDB 确实是通过子进程来进行的,具体做了什么呢?官网写得很清楚
How it works
Whenever Redis needs to dump the dataset to disk, this is what happens:
1.Redis forks. We now have a child and a parent process.
2.The child starts to write the dataset to a temporary RDB file.
3.When the child is done writing the new RDB file, it replaces the old one.
This method allows Redis to benefit from copy-on-write semantics.从整体上,是做了以下事项:
Fork 出一个子进程来专门做 RDB 持久化
子进程写数据到临时的 RDB 文件
写完之后,用新 RDB 文件替换旧的RDB文件。
整体流程如下:
下面还有一句:This method allows Redis to benefit from copy-on-write semantics.
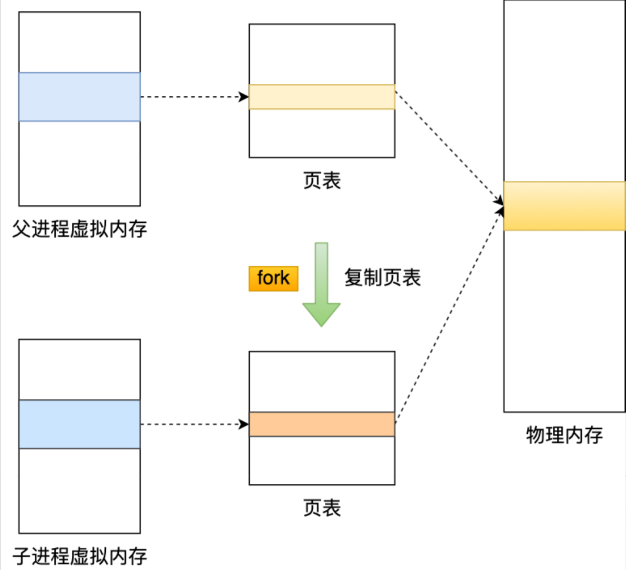
就是说这种方式让Redis从写时复制技术受益,Redis官方文档基本没废话,这句话看似无关轻重,实际上说明了:执行 RDB持久化过程中,Redis 依然可以继续处理操作命令的,也就是数据是能被修改的,这就是通过写时复制技术实现的。
具体而言:fork 创建子进程之后,通过写时复制技术,子进程和父进程是共享同一片内存数据的,因为创建子进程的时候,会复制父进程的页表,但是页表指向的物理内存还是一个。
只有在发生修改内存数据的情况时,物理内存才会被复制一份。
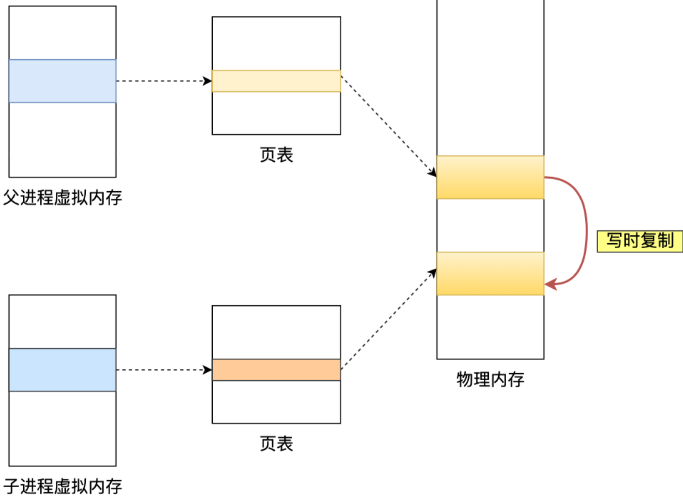
就是这样,Redis 使用 bgsave 对当前内存中的所有数据做快照,这个操作是由 bgsave 子进程在后台完成的,执行时不会阻塞父进程中的主线程,这就使得主线程同时可以修改数据。
这样的目的是为了减少创建子进程时的性能损耗,从而加快创建子进程的速度,毕竟创建子进程的过程中,是可能阻塞主线程的。
可以看到,复制期间,读数据互不影响,如果有写操作发生,则主进程复制一份内存,在这个复制的内存基础上,主进程再修改原来的数据,子进程持久化的依然是修改之前的数据。
AOF 详解#
怎么开启 AOF#
打开 redis 配置文件,例如 /usr/local/etc/redis.conf,
在其中可以看到如下配置:
appendonly no
# The name of the append only file (default: "appendonly.aof")
appendfilename "appendonly.aof"appendonly 设置为yes,即可打开AOF,从这个现象来看,可以看到Redis官方认为RDB绝大多数时候都还是需要的,而AOF更依赖实际的业务场景。
appendonly yes打开之后,Redis每条更改数据的操作都会记录到AOF文件中,当你重启,AOF会助你重建状态,相当于就是请求全部重放一次,所以AOF恢复起来会比较慢。
AOF写入流程#
从上面的描述,我们可以看出,执行请求时,每条日志都会写入到AOF。

这不免会让人担心,是否会影响Redis的执行性能,答案是肯定的,多了一步操作,或多或少都会带来些损耗,但是Redis实际是提供了不同的策略来选择不同程度的损耗。这里我们先从比较的宏观视角,介绍Redis提供的 3 种刷盘策略,以便根据需要进行不同的选择。
appendfsync always,每次请求都刷入AOF,用官方的话说,非常慢,非常安全appendfsync everysec,每秒刷一次盘,用官方的话来说就是足够快了,但是在崩溃场景下你可能会丢失1秒的数据。appendfsync no,不主动刷盘,让操作系统自己刷,一般情况Linux会每30秒刷一次盘,这种策略下,可以说对性能的影响最小,但是如果发生崩溃,可能会丢失相对比较多的数据。
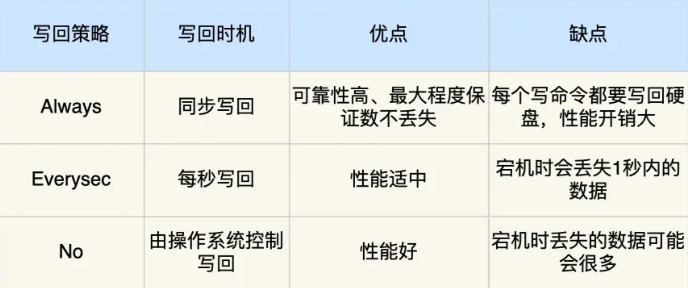
Redis 官方建议是方案二,也就是每秒刷一次盘,这种方式下速度也足够快了,同时崩溃时损失的数据只有1s,这在大多数场景都是可以接受的。
当然了,我们要根据实际业务来选择,比如就是做简单的缓存,并且不存在什么超级热点缓存,那么丢失30秒也不是什么大事,这时候如果追求性能的机制,可以选择方案3。
方案一说实话倒是很少有场景会使用,因为Redis本身是无法做到完全不丢数据,Redis的定位就不是完全可靠,通常也就没必要损耗大量性能去追求立刻刷盘。
写入 AOF 细节#
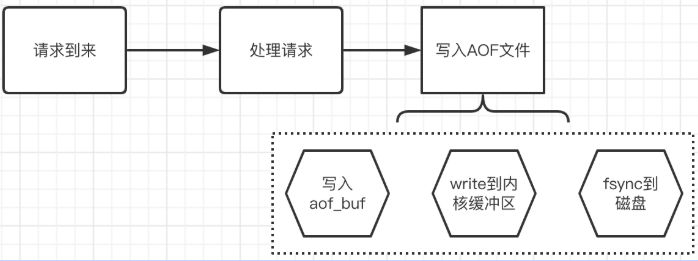
写入AOF,其实是分了好几步来的。
第一步:其实是将数据写入 AOF 缓存中,这个缓存名字是 aof_buf,其实就是一个 sds 数据
sds aof_buf; /* AOF buffer, written before entering the event loop */第二步:aof_buf 对应数据刷入磁盘缓冲区,什么时候做这个事情呢?事实上,Redis 源码中一共有4个时机,会调用一个叫 flushAppendOnlyFile 的函数,这个函数会使用 write 函数来将数据写入操作系统缓冲区:
- 处理完事件处理后,等待下一次事件到来之前,也就是beforeSleep中。
- 周期函数serverCron中,这也是我们打过很多次交道的老朋友了
- 服务器退出之前的准备工作时
- 通过配置指令关闭AOF功能时
第三步:刷盘,即调用系统的 flush 函数,刷盘其实还是在flushAppendOnlyFile函数中,是在write之后,但是不一定调用了flushAppendOnlyFile,flush就一定会被调用,这里其实是支持一个刷盘时机的配置,这一步受刷盘策略影响是最深的,如下面代码所示,如果是appendfsync always策略,那么就立刻调用redis_fsync刷盘,如果是AOF_FSYNC_EVERYSEC策略,满足条件后会用aof_background_fsync使用后台线程异步刷盘。
/* Perform the fsync if needed. */
if (server.aof_fsync == AOF_FSYNC_ALWAYS) {
/* redis_fsync is defined as fdatasync() for Linux in order to avoid
* flushing metadata. */
latencyStartMonitor(latency);
redis_fsync(server.aof_fd); /* Let's try to get this data on the disk */
latencyEndMonitor(latency);
latencyAddSampleIfNeeded("aof-fsync-always",latency);
server.aof_last_fsync = server.unixtime;
} else if ((server.aof_fsync == AOF_FSYNC_EVERYSEC &&
server.unixtime > server.aof_last_fsync)) {
if (!sync_in_progress) aof_background_fsync(server.aof_fd);
server.aof_last_fsync = server.unixtime;
}讲到这里,我们应该可以很清晰画出一个相对宏观的完整写入示意图:
下面,我们来看一个AOF写入例子,以进一步掌握AOF。
AOF 例子#
执行如下命令:
127.0.0.1:6379> set city sz
OK
127.0.0.1:6379> hset mart a b
(integer) 1
127.0.0.1:6379> hset mart c d
(integer) 1对应会生成了如下的AOF文件:
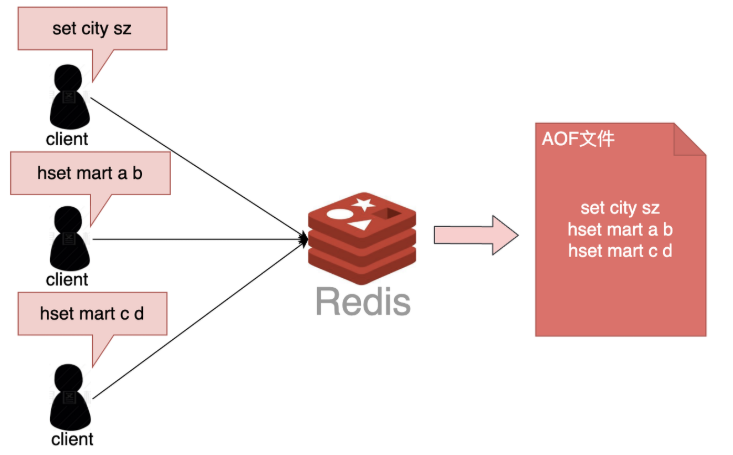
打开 aof 文件可以看到:
commands are logged using the same format as the Redis protocol itself.aof 记录的方式,和 Redis 协议本身是一样的,可以看到这个协议可读性还是比较强的。
*3
$3
set
$4
city
$2
sz
*4
$4
hset
$4
mart
$1
a
$1
b
*4
$4
hset
$4
mart
$1
c
$1
dAOF 重写#
AOF是不断写入的,这很容易带来一个疑问,如此下去AOF不是会不断膨胀吗?
针对这个问题,Redis采用了重写的方式来解决:
Redis可以在AOF文件体积变得过大时,自动地在后台Fork一个子进程,专门对AOF进行重写。说白了,就是针对相同Key的操作,进行合并,比如同一个Key的set操作,那就是后面覆盖前面。
注意这里的合并是逻辑上的合并,实际操作是从数据库读取数据,生成一份新的AOF文件。
在重写过程中,Redis不但将新的操作记录在原有的AOF缓冲区,而且还会记录在AOF重写缓冲区。一旦新AOF文件创建完毕,Redis 就会将重写缓冲区内容,追加到新的AOF文件,再用新AOF文件替换原来的AOF文件。
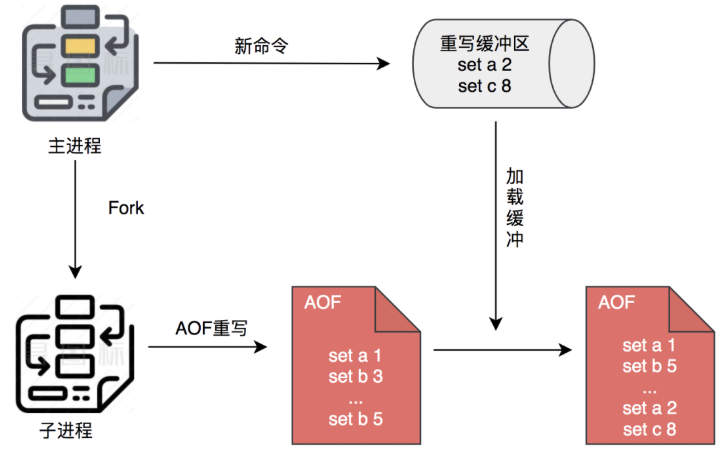
AOF缓冲区不可以替代AOF重写缓冲区的原因是AOF重写缓冲区记录的是从重写开始后的所有需要重写的命令,而AOF缓冲区可能只记录了部分的命令。
这里可能会问,AOF达到多大会重写,实际上,这也是配置决定,默认如下,同时满足这两个条件则重写。
# 相比上次重写时候数据增长100%
auto-aof-rewrite-percentage 100
# 超过
auto-aof-rewrite-min-size 64mb也就是说,超过64M的情况下,相比上次重写时的数据大一倍,则触发重写,很明显,最后实际上还是在周期函数来检查和触发的。
RDB 和 AOF 的本质区别是什么?#
如果是讲区别可以从 文件类型,文件恢复速度,安全性 来进行回答,但本质区别就是 RDB 是使用快照进行持久化,AOF是日志。
其他可以列举的区别点 都是能从 快照 与 日志 中的对比找出的
- 文件类型:RDB生成的是 二进制文件(快照),AOF生成的是 文本文件(追加日志)
- 安全性:缓存宕机时,RDB 容易丢失较多的数据,AOF 根据策略决定(默认的everysec 可以保证最多有一秒的丢失)
- 文件恢复速度:由于RDB是二进制文件,所以恢复速度也比 AOF更快
- 操作的开销:每一次RDB保存都是一次全量保存,操作比较重,通常设置至少5分钟保存一次数据。而AOF的刷盘是一次追加操作,操作比较轻,通常设置策略为每一秒进行一次刷盘
回答#
本质区别就是 RDB 是保存快照进行持久化,而 AOF 则是 追加日志文件进行持久化。因为这个本质区别,所以还会有文件恢复速度、安全性、操作开销等区别,需要展开讲吗?(这里其实摸不准面试官想法,所以可以询问一下)
如果RDB和AOF只能选一种,你选哪个?#
两个方向分析:
性能和可靠 之间做一个选择
分析Redis为什么默认打开的是RDB,以及在只开一个情况,实际是更推荐RDB的。
回答#
如果从业务需要来看,如果我们能接受分钟级别的数据丢失,可以考虑选择RDB,如果需要尽量保证数据安全,可以考虑混合持久化,如果只用AOF,那么优先选择everysec策略进行刷盘(在可靠和性能之间有一个平衡)。
从持久化理念来看,始终开启快照是一个推荐的方式,这也是Redis官方为什么默认开启RDB,而不开启AOF,同时官网也明确不推荐只开AOF
介绍一下 AOF 的三种写回策略#
回答#
Always、Everysec 和 No,这三种策略在可靠性上是从高到低,而在性能上从低到高。
Always是每次写操作命令执行完后,同步将 AOF 日志数据写回硬盘;Everysec每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,然后每隔一秒将缓冲区里的内容写回到硬盘;No就是不控制写回硬盘的时机。每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,再由操作系统决定何时将缓冲区内容写回硬盘。
为什么先执行 Redis 命令,再把数据写入 AOF 日志呢?#
好处:
- 保证正确写入:如果当前的命令语法有问题,错误的命令记录到 AOF 日志里后可能还会进行语法检查。先执行Redis命令,再把数据写入AOF日志可以保证写入的都是正确可执行的命令。
- 不阻塞当前写操作:因为当写操作命令执行成功后才会将命令记录到AOF日志,避免写入阻塞。
缺陷:
- 数据可能会丢失: 执行写操作命令和记录日志是两个过程,Redis还没来得及将命令写入到硬盘时发生宕机,数据会有丢失的风险。
- 阻塞其他操作: 不会阻塞当前命令的执行,但因为 AOF 日志也是在主线程中执行,所以当 Redis 把日志文件写入磁盘的时候,还是会阻塞后续的操作无法执行。
回答#
有2点好处。
- 保证正确写入:如果当前的命令语法有问题,错误的命令记录到 AOF 日志里后可能还会进行语法检查。先执行Redis命令,再把数据写入AOF日志可以保证写入的都是正确可执行的命令。
- 不阻塞当前写操作:因为当写操作命令执行成功后才会将命令记录到AOF日志,避免写入阻塞。
AOF子进程的内存数据跟主进程的内存数据不一致怎么办?#
Redis 的重写 AOF 过程是由后台子进程 bgrewriteaof 来完成的,这有两个好处:
- 子进程进行 AOF 重写期间,主进程可以继续处理命令请求,从而避免阻塞主进程;
- 子进程带有主进程的数据副本,使用子进程而不是线程,因为如果是使用线程,多线程之间会共享内存,那么在修改共享内存数据的时候,需要通过加锁来保证数据的安全,而这样就会降低性能。创建子进程时,父子进程是共享内存数据的,不过这个共享的内存只能以只读的方式,而当父子进程任意一方修改了该共享内存,会发生写时复制,于是父子进程就有了独立的数据副本,不用加锁来保证数据安全。
AOF 子进程产生的时刻,数据和主进程是一致的,这里面试官是想问重写过程中主进程数据增加了,如何保持最后结果一致,回答的关键在 AOF 重写缓冲区。
回答#
Redis设置了一个 AOF 重写缓冲区,这个缓冲区在创建 bgrewriteaof 子进程之后开始使用。在重写 AOF 期间,当 Redis 执行完一个写命令之后,它会同时将这个写命令写入到AOF 缓冲区和AOF 重写缓冲区。当子进程完成 AOF 重写工作后,会向主进程发送一条信号。主进程收到该信号后,会调用一个信号处理函数,将 AOF 重写缓冲区中的所有内容追加到新的 AOF 的文件中,使得新旧两个 AOF 文件所保存的数据库状态一致;新的 AOF 的文件进行改名,覆盖现有的 AOF 文件。
RDB 在执行快照的时候,数据能修改吗?#
推荐学习官网对RDB行为的说明
How it works
Whenever Redis needs to dump the dataset to disk, this is what happens:
1.Redis forks. We now have a child and a parent process.
2.The child starts to write the dataset to a temporary RDB file.
3.When the child is done writing the new RDB file, it replaces the old one.
This method allows Redis to benefit from copy-on-write semantics.注意最后一句话:
This method allows Redis to benefit from copy-on-write semantics.
就是说这种方式让Redis从写时复制技术受益,Redis官方文档基本没废话,这句话看似无关轻重,实际上说明了:执行 RDB持久化过程中,Redis 依然可以继续处理操作命令的,也就是数据是能被修改的,这就是通过写时复制技术实现的。
回答#
可以。执行 bgsave 过程中,Redis 依然可以继续处理操作命令的,数据是能被修改的,采用的是写时复制技术(Copy-On-Write, COW)。执行 bgsave 命令的时候,会通过 fork() 创建子进程,此时子进程和父进程是共享同一片内存数据的,因为创建子进程的时候,会复制父进程的页表,但是页表指向的物理内存还是一个,由于共享父进程的所有数据,可以直接读取主线程里的内存数据,并将数据写入到 RDB 文件。此时如果主线程执行读操作,则主线程和 bgsave 子进程互相不影响。如果主线程要修改共享数据里的某一块数据,就会发生写时复制,数据的物理内存就会被复制一份,主线程在这个数据副本进行修改操作。与此同时,子进程可以继续把原来的数据写入到 RDB 文件。
Redis用RDB持久化时对过期键会如何处理的?#
在 Redis 使用 RDB(Redis Database Backup)持久化 时,过期键 的处理方式取决于 RDB 生成和恢复的阶段,具体情况如下:
- Redis 在 生成 RDB 快照时,不会 直接删除过期的键,而是检查每个 key 的 TTL,如果某个 key 已经过期,则 不会写入 RDB 文件;如果 key 未过期,则会 连同其 TTL 一起写入 RDB。这样,生成的 RDB 文件中 不会包含已过期的键,避免存储无用数据。
- 当 Redis 重启并加载 RDB 文件 时:Redis 会 正常加载所有 key 及其 TTL,但不会立即清理所有过期 key,而是由数据清理机制来保证(在客户端访问 key 时,Redis 发现 key 已过期,则立即删除。Redis 运行时的定期清理机制 可能也会被触发,主动删除过期 key)
回答#
RDB 分为生成阶段和加载阶段,生成阶段会对 key 进行过期检查,过期的 key 不会保存到RDB文件中;加载阶段在载入 RDB 文件时,Redis 会正常加载所有 key 及其 TTL,而过期 Key 的删除,是由专门的数据清理机制来保证,和RDB无关。
Redis用AOF持久化时对过期键会如何处理的?#
总结为下表:
| 阶段 | AOF 处理方式 |
|---|---|
| AOF 追加日志 | 记录 EXPIRE 命令,过期后不自动删除,只有触发惰性删除或定期清理时才写入 DEL |
| AOF 重写 | 过滤掉已过期的 key,生成更精简的 AOF 文件 |
| AOF 恢复 | 加载 AOF 时仍然恢复所有 key,过期 key 需要等待惰性删除或定期清理 |
回答#
恢复时会恢复所有 过期key,等待惰性删除或定期清理,写入时会记录EXPIRE命令,当此过期键被删除后,Redis 会向 AOF 文件追加一条 DEL 命令来显式地删除该键值。重写阶段会对 Redis 中的键值对进行检查,已过期的键不会被保存到重写后的 AOF 文件中。
AOF模式下,Redis主从模式中,对过期键会如何处理?#
主库会记录一条 del 指令到 AOF 文件,从库也会同步这条指令
回答#
从库不会进行过期扫描,从库的过期键处理依靠主服务器控制,主库在 key 到期时,会在 AOF 文件里增加一条 del 指令,同步到所有的从库,从库通过执行这条 del 指令来删除过期的 key。
如果主从同步发生意外,原本主库的 key 过期了,但是 del 指令没有同步给从库成功,导致从库内存中存在已经过期但没有删除的 key,这时候有客户端访问从库时,即使 key 还是内存的,但是从库发现 key 是过期的,就不会返回 key 的数据给客户端了。
RDB持久化的触发时机?#
主要有这么几个地方,一个是调用 save 或者 bgsave 命令,一个是根据我们配置周期进行,一个是Redis关闭之前,这三个是比较常见的,其它边缘一点的还有主从全量复制发送RDB文件等。(如果追问可以再说还有客户端执行数据库清空命令FLUSHALL)
AOF混合持久化方案是什么?#
需要记住的时,AOF 混合持久化,就是在 AOF 重写的基础上 做了一些改动
回答#
- AOF混合持久化 会使用RDB持久化函数 将内存数据写入到新的AOF文件中 (数据格式也是RDB格式)
- 而重写期间 新的写入命令 追加到 新的AOF文件 仍然是AOF格式
- 此时新的AOF文件 就是 由 RDB格式 和 AOF格式组成的 日志文件
简单描述AOF重写流程#
AOF重写就三个关键点:
- 子进程读取Redis DB中的数据以字符串命令的格式(也可以看作AOF文件格式)写入到新AOF文件中;
- 如果有新数据,由主进程将数据写入到aof重写缓冲区(aof_rewrite_buf)
- 当子进程完成重写操作后,主进程通过管道将aof重写缓冲区中的数据传输给子进程,然后子进程追加到新aof文件中
回答#
当 aof 重写触发那一刻,主进程就会 fork 出一个子进程,然后这个子进程读取 Redis DB 中的数据,以字符串命令的格式写入到新 AOF 文件中
如果这个时候 Redis 接收到了新的写入命令,那么主进程会将这些"增量数据"写入到AOF重写缓冲区中
在子进程将数据都写入到新AOF文件后,主进程会通过管道将AOF重写缓冲区里面的数据发送给子进程,子进程再将这一份数据追加到新AOF文件中,保证新AOF文件的完整性。
AOF重写你觉得有什么不足之处么?#
重写期间 新的写命令,会将数据写入到两处地方(AOF缓冲和AOF重写缓冲)中,这是额外的CPU和内存开销;
重写时会将AOF 缓冲 和 AOF重写缓冲 分别 写入到 旧日志 和 新日志中,这是额外的磁盘开销
除了清楚 AOF的不足之处,如果还知道改进方案,那么会令面试官刮目相看,Redis 7.0就对此做了新的改进。
回答#
我认为主要有3点不足之处:
- 额外的 CPU 开销:
- 在重写时,主进程需要将新的写入数据 写入到 AOF重写缓冲(aof_rewrite_buf)
- 主进程 需要通过管道向子进程发送AOF重写缓冲的数据
- 子进程还需要将这些数据 写入到新的AOF日志中
- 额外的内存开销:在重写时,AOF缓冲 和 AOF重写缓冲 中的数据都是一样的(浪费了一份)
- 额外的磁盘开销:在重写时,AOF缓冲需要刷入 旧的AOF日志,AOF重写缓冲也需要刷入 到新的AOF日志,导致在重写时磁盘多占一份数据
Redis在7.0版本也做了对应的优化,我可以讲一下吗?
针对AOF重写的不足,你有什么优化思路呢?#
改进之处:
在Redis 7.0版本,对AOF重写作出了优化,提出了 MP-AOF 方案,原来的AOF重写缓冲被移除,AOF日志也分成了 Base AOF日志 ,Incr AOF日志
MP-AOF: Multi Part AOF = one BASE AOF + many INCR AOFs
Base AOF日志 记录重写之前的命令;Incr AOF 日志记录 重写时 新的写入命令(正常AOF刷盘的时候写的是Incr AOF)
当重写发生时,主进程fork出一个 子进程,对Base AOF日志 进行重写(将当前内存数据写入到新的Base AOF日志);如果此时有新的写入命令,会由主进程 写入到aof_buf,再将缓冲数据刷入 新的Incr AOF日志。这样 新的Incr AOF日志 + 新的Base AOF日志 就构成了完整的新的AOF日志
子进程重写 结束时,主进程会负责更新 manifest 文件,将新生成的 BASE AOF 和 INCR AOF 信息加进清单,并将之前的 BASE AOF 和 INCR AOF 标记为 HISTORY。
mianfest 用于追踪管理AOF文件
这些 HISTORY 文件默认会被 Redis 异步删除(unlink),一旦 manifest 文件更新完成,就代表着整个 AOFRW 流程结束
回答#
其实在 Redis 7.0 版本,就使用 MP-AOF 方案对 AOF 重写做了优化,核心其实就是去掉原来的重写缓冲,同时将AOF日志拆分为 Base AOF日志 ,Incr AOF日志,由manifest来管理。重写时,还是开一个子进程,对Base AOF日志 进行重写,但是新命令会往 新的Incr AOF日志写,Incr AOF日志 + 新的Base AOF日志 就构成了完整的新的AOF日志。
